Time series modelling#
Statistical modelling of time series data involves the analysis and interpretation of data points collected sequentially over time.
Time series data often exhibit patterns such as trends, seasonal variations, and irregular fluctuations, making them inherently complex to analyze.
There exist many statistical models of time series. For example, autoregressive integrated moving average (ARIMA), exponential smoothing methods, and state space models. These models allow to forecast future values based on past observations.
ARIMA is an abbreviation for autoregressive integrated moving average and these models are what it says on the tin : they include autoregressive, differencing, and moving average components.
A common way to work with time series data, is to decompose it into the trend \(t_t\) and seasonality \(s_t\) components, and then model the residual random effect with ARIMA. We can view the trend and seasonality parts as the fixed effect of the model, and the residual effect as the random effect. For example
Here \(r\) is the seasonality period.
The example above shows only one harmoic as a part of the seasonality term \(s_t = \beta_2 \sin\left(\frac{2\pi}{r}t\right)\). However, one can of course include higher order harmonics as well, each of them contributing to the design matrix within the regression problem:
In this lecture we are interested in looking at time series structure through the temporal random effects lens. I.e. we assume that trend and seasonality have already been deducted \(x_t := y_t - \mu_t\). We will consider a specific subclass of ARIMA family. Namely, the autoregressive models.
Autoregressive models are statistical models that use a linear combination of past observations of a time series \(x_{t-1}, x_{t-2},... \) to predict future values, where each observation is regressed on previous observations.
Autoregressive model of order 1, AR(1)#
AR(1) definition#
Let us consider AR(1), or Autoregressive model of order 1. In an AR(1) model, each value in the time series \(x_t\) is modeled as a linear combination of the previous observation \(x_{t-1}\) and a random error term \(\epsilon_t\). Mathematically, an AR(1) process can be represented as
The innovations \(\epsilon_t\) are independent from each other.
The condition \(\mid \phi \mid <1\) here is required for stationarity. In order to ensure stationarity, we need to check that all roots of the characterictic polynomial \(\lambda_i\) satisfy \(|\lambda_i|>1.\) If \(B\) is the backshift operator, such that \(B^k = X_{t-k}\), we can rewrite the AR(1) model as
The characteristic polynimial in this case takes the form \(f(\lambda) = 1 - \phi \lambda\). Its roots are obtained by solving \(1 - \phi\lambda = 0\). Hence, \(\lambda= \frac{1}{\phi}\).
In many modelling cases, the knowledge of this formulation will suffice for modelling. There is a lot of interesting maths related to AR models, but we will look at that later. Right now, we are ready to implement AR(1).
AR(1) implementation#
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import jax
import jax.numpy as jnp
import numpyro
from numpyro import distributions as dist
from numpyro.infer import MCMC, NUTS
/opt/hostedtoolcache/Python/3.11.11/x64/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Let’s simulate data from AR(1) model.
def simulate_ar1(phi, sigma, n):
"""
simulate time series data from an AR(1) model.
parameters:
- phi (float): autoregressive coefficient. Requires -1 < phi < 1.
- sigma (float): standard deviation of the white noise.
- n (int): length of the time series.
returns:
np.ndarray: simulated time series data.
"""
# initialize array to store simulated data
ts_data = np.zeros(n)
# generate white noise
noise = np.random.normal(0, sigma, n)
# generate data points using AR(1) process
for i in range(1, n):
ts_data[i] = phi * ts_data[i-1] + noise[i]
return ts_data
# parameters for AR(1) model
phi_true = 0.7
sigma_true = 1.0
n = 200
# simulate AR(1) time series data
ts_data = simulate_ar1(phi_true, sigma_true, n)
plt.figure(figsize=(6, 4))
plt.plot(ts_data, color='teal')
plt.title("Simulated AR(1) time series (phi={}, sigma={})".format(phi_true, sigma_true))
plt.xlabel("time $t$")
plt.ylabel("value $x_t$")
plt.grid(True)
plt.show()
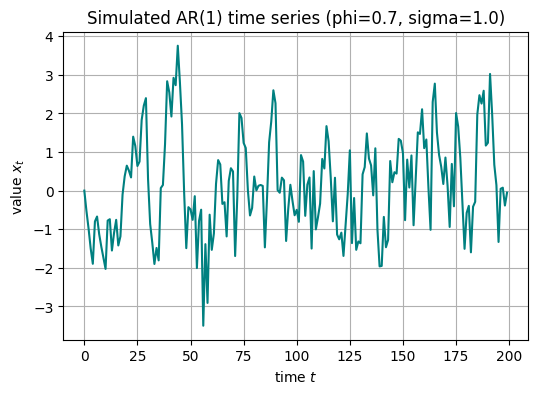
Can we fit a Numpyro model to this data to estimate \(\phi\) and \(\sigma\)?
def ar1_model(ts_data=None):
# priors for AR(1) parameters
phi = numpyro.sample('phi', dist.Normal(0, 1)) # this prior is not quite right. Can you spot why?
sigma = numpyro.sample('sigma', dist.HalfNormal(1))
# AR(1) model
with numpyro.plate('data', len(ts_data) - 1):
numpyro.sample('obs', dist.Normal(phi * ts_data[:-1], sigma), obs=ts_data[1:])
# inference
nuts_kernel = NUTS(ar1_model)
mcmc = MCMC(nuts_kernel, num_warmup=500, num_samples=1000, progress_bar=False)
mcmc.run(jax.random.PRNGKey(0), ts_data=ts_data)
mcmc.print_summary()
mean std median 5.0% 95.0% n_eff r_hat
phi 0.66 0.05 0.67 0.58 0.75 854.81 1.00
sigma 0.97 0.05 0.97 0.89 1.05 592.34 1.00
Number of divergences: 0
# posterior predictive samples
posterior_samples = mcmc.get_samples()
phi_samples = posterior_samples['phi']
sigma_samples = posterior_samples['sigma']
posterior_predictive_samples = []
for phi, sigma in zip(phi_samples, sigma_samples):
ts_data_pred = simulate_ar1(phi, sigma, n)
posterior_predictive_samples.append(ts_data_pred)
# plot posterior predictive samples
plt.figure(figsize=(10, 6))
for sample in posterior_predictive_samples:
plt.plot(sample, alpha=0.05, color='orange')
plt.plot(ts_data, label='Original Time Series', color='teal')
plt.title("Posterior Predictive Samples")
plt.ylim(-8,8)
plt.xlabel("$t$")
plt.ylabel("$x_t$")
plt.legend()
plt.grid(True)
plt.show()
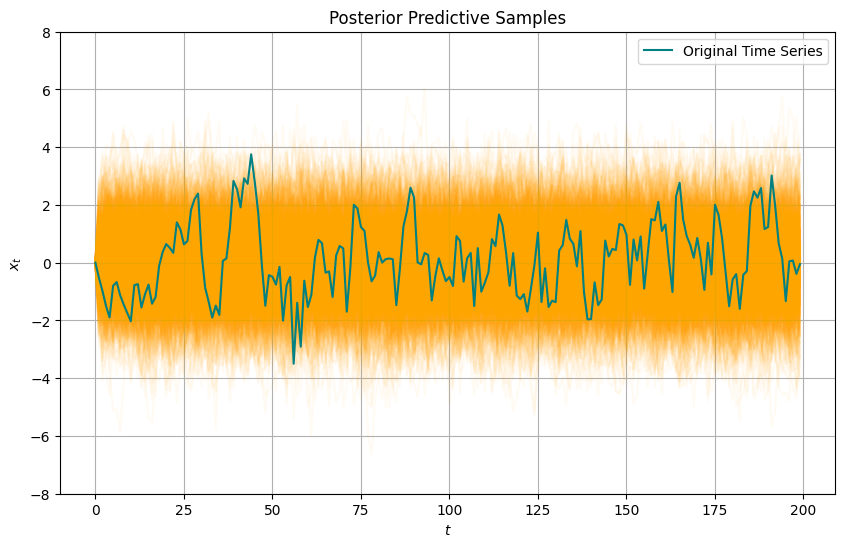
Group Task
Obtain posterior predictive samples using the Predictive command. Visualiase the posterior predictive samples.
Are we happy with this posterior predictive?
plt.figure(figsize=(10, 4))
# plot posterior of phi
plt.subplot(1, 2, 1)
sns.kdeplot(phi_samples, fill=True)
plt.axvline(x=phi_true, color='r', linestyle='--', label='True value')
plt.xlabel('$\phi$')
plt.ylabel('Density')
plt.title('Posterior of parameter $\phi$')
# plot posterior of sigma
plt.subplot(1, 2, 2)
sns.kdeplot(sigma_samples, fill=True)
plt.axvline(x=sigma_true, color='r', linestyle='--', label='True value')
plt.xlabel('$\sigma$')
plt.ylabel('Density')
plt.title('Posterior of parameter $\sigma$')
plt.tight_layout()
plt.show()
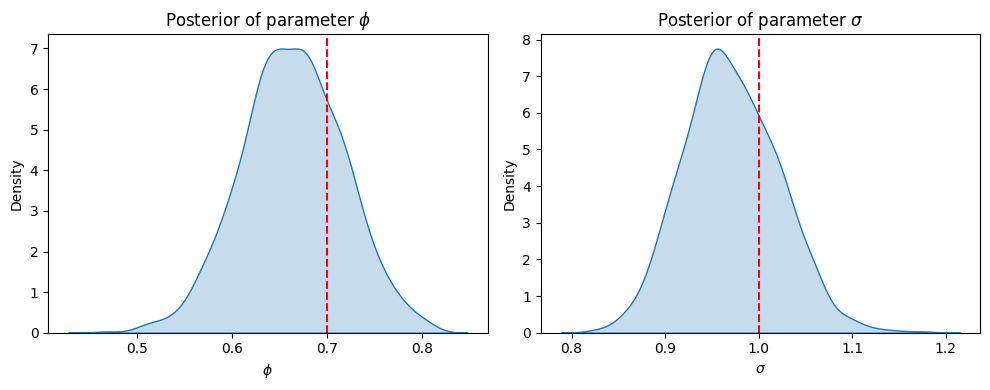
Group Task
Experiment with the number of observed data points n. How does it affect the estimate of parameter \(\phi\)?
AR(1) joint density and precision matrix#
We can derive that
Joint density of \(x_1, ..., x_T\), therefore, has the form
The exponent is a quadratic form of \(x_1, ..., x_T:\)
This quadratic form corresponds to the matrix
Two observations about this matrix are important:
its values do not depend on \(T\), which is nice propery from modelling perspective: regardless of the number of observed time points, this will always be the same matrix.
The matrix \(Q\) is sparse and is tridiagnoal or banded .
We could have guessed the banded straucture of AR(1) in advance. This is how:
In general, an element \((i,j)\) of a precision matrix is equal to zero, if and only if \(x_i\) and \(x_j\) are conditionally independent (i.e. they are independent, given all other entries of vector \(x\), accept for \(x_i\) and \(x_j\); this is usually denoted as \(x_{-\{i,j\}}\)). Hence, \(Q_{(i,j)} = 0\) if and only if partial correlation of \(x_i\) and \(x_j\) equals zero. Partial autocorrelation (PAC) of an AR(p) process for lags greater than \(p\), equals zero. It follows, that an AR(1) precision matrix has banded structure with non-zeros covering the diagonal, one line above the diagonal, and one below.
Group Task
What do you think the sparcity pattern will be in the precision matrix of the AR(2) process?
Autoregressive model of order 2, AR(2)#
AR(2) definition#
AR(2) process \(x_t\) can be formulated mathematically as
Sometimes it is more convenient to reparametrise AR(2) as
where \(\mu \in R, \lambda \in (0,1).\)
AR(2) checking stationarity#
Let us find conditions on model parameters when AR(2) will be stationary.
For an autoregressive process to be stationary, the roots of its characteristic polynomial (polynomial of the backshift operator \(B\)) needs to lie outside of the unit circle. The characteristic polynomial here has the form \(\Gamma(z) = 1 - \gamma_1 z - \gamma_2 z^2.\) Lengths of its roots are
If \(\lambda(\lambda-1) \ge 0,\) i.e. \(\lambda \ge 1\) or \(\lambda \le 0,\) then the second root \(z_2\) lies within the unit circle and the process is non-stationary. If \(\lambda \in (0,1),\) then \(\sqrt{\lambda(\lambda-1)} = i \sqrt{\lambda(1-\lambda)},\) and \(\vert z_{1,2} \vert = \left\rvert 1 \pm i \sqrt{\frac{\lambda}{1-\lambda}} \right\rvert = 1 + \frac{\lambda}{1-\lambda} = \frac{1}{1-\lambda},\) which is greater than \(1\) for all \(\lambda \in (0,1).\)
AR(2) joint density and precision matrix#
All innovations \(\epsilon_t\) are independent from each other and stationarity conditions are satisfied. As before,
Task 24
Continue from here and derive precision matrix of AR(2) for \(T=5\).
Hint: before computing the matrix, can we predict anything about its structure?
What can we say about this matrix if \(\phi_2=0\)?
AR(2) implementation#
# generate synthetic data
phi1_true = 0.6
phi2_true = -0.3
sigma_true = 0.1
x0 = 0.0
x1 = 0.0
num_samples = 100
noise = jax.random.normal(jax.random.PRNGKey(0), shape=(num_samples,))
x = jnp.zeros(num_samples)
x = x.at[0].set(x0)
x = x.at[1].set(x1)
for t in range(2, num_samples):
x = x.at[t].set(phi1_true * x[t-1] + phi2_true * x[t-2] + sigma_true * noise[t])
plt.figure(figsize=(6, 4))
plt.plot(x, color='teal')
plt.title("Simulated AR(2) time series\n (phi1={}, phi2={}, sigma={})".format(phi1_true, phi2_true, sigma_true))
plt.xlabel("$t$")
plt.ylabel("$x_t$")
plt.grid(True)
plt.show()
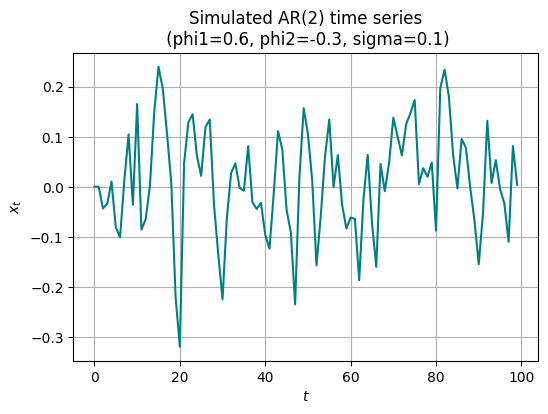
def ar2_model(x):
# priors for AR coefficients
phi1 = numpyro.sample('phi1', dist.Normal(0, 1))
phi2 = numpyro.sample('phi2', dist.Normal(0, 1))
sigma = numpyro.sample('sigma', dist.Exponential(1))
# define the AR(2) process
for t in range(2, len(x)):
mean = phi1 * x[t-1] + phi2 * x[t-2]
numpyro.sample(f'x_{t}', dist.Normal(mean, sigma), obs=x[t])
# inference
nuts_kernel = NUTS(ar2_model)
mcmc = MCMC(nuts_kernel, num_warmup=500, num_samples=1000, progress_bar=False)
mcmc.run(jax.random.PRNGKey(42), x=x)
mcmc.print_summary()
mean std median 5.0% 95.0% n_eff r_hat
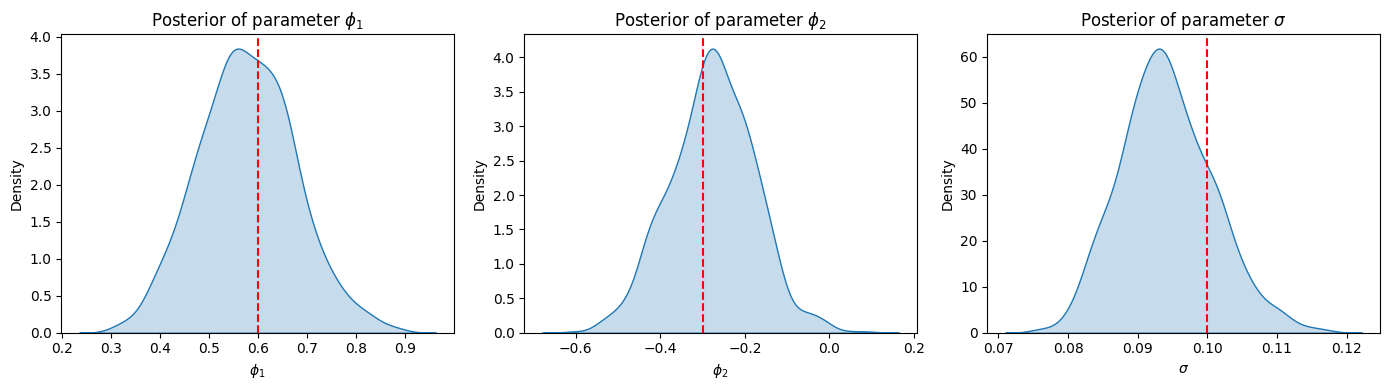
phi1 0.58 0.10 0.57 0.40 0.73 747.37 1.00
phi2 -0.28 0.10 -0.27 -0.44 -0.13 879.04 1.00
sigma 0.09 0.01 0.09 0.08 0.10 807.46 1.00
Number of divergences: 0
posterior_samples = mcmc.get_samples()
phi1_samples = posterior_samples['phi1']
phi2_samples = posterior_samples['phi2']
sigma_samples = posterior_samples['sigma']
plt.figure(figsize=(14, 4))
# plot posterior of phi1
plt.subplot(1, 3, 1)
sns.kdeplot(phi1_samples, fill=True)
plt.axvline(x=phi1_true, color='r', linestyle='--', label='True value')
plt.xlabel('$\phi_1$')
plt.ylabel('Density')
plt.title('Posterior of parameter $\phi_1$')
# plot posterior of phi2
plt.subplot(1, 3, 2)
sns.kdeplot(phi2_samples, fill=True)
plt.axvline(x=phi2_true, color='r', linestyle='--', label='True value')
plt.xlabel('$\phi_2$')
plt.ylabel('Density')
plt.title('Posterior of parameter $\phi_2$')
# plot posterior of sigma
plt.subplot(1, 3, 3)
sns.kdeplot(sigma_samples, fill=True)
plt.axvline(x=sigma_true, color='r', linestyle='--', label='True value')
plt.xlabel('$\sigma$')
plt.ylabel('Density')
plt.title('Posterior of parameter $\sigma$')
plt.tight_layout()
plt.show()
Random walk model#
Another class of widely used models for time series data is the random walk. It is a stochastic process where future values are dependent on the current value and a random shock. Here’s a description of the random walk model:
Here \(\epsilon_t\) are the innovations which are independent from all previous values of \(x_i, i <= t-1.\) Commonly it is assumed that
Under the random walk model each new value depends on the previous value plus a random shock. It implies that future values are unpredictable based solely on past values, making it non-stationary. Despite its simplicity, it’s widely used in various fields like finance. The model captures trends and path-dependent volatility but doesn’t account for other factors influencing the series.
As a result of adding a random shock to the current value to obtain the next value, the random walk model implies that future values are unpredictable based solely on the past values. The randomness introduced by the shocks makes the series non-stationary.
The random walk model is non-stationary because its variance changes over time:
Let us illustrate random walk model with a simulation.
import numpy as np
import matplotlib.pyplot as plt
def simulate_random_walk(num_steps, sigma):
# generate random shocks
shocks = np.random.normal(0, sigma, size=num_steps)
# accumulate shocks to get the random walk path
random_walk = np.cumsum(shocks)
return random_walk
# parameters
num_steps = 100
sigma = 1.0
# simulate random walk data
random_walk_data = simulate_random_walk(num_steps, sigma)
plt.figure(figsize=(8, 6))
plt.plot(random_walk_data, marker='o', linestyle='-', color='teal')
plt.title("Simulated random walk")
plt.xlabel("$t$")
plt.ylabel("$x_t$")
plt.grid(True)
plt.show()
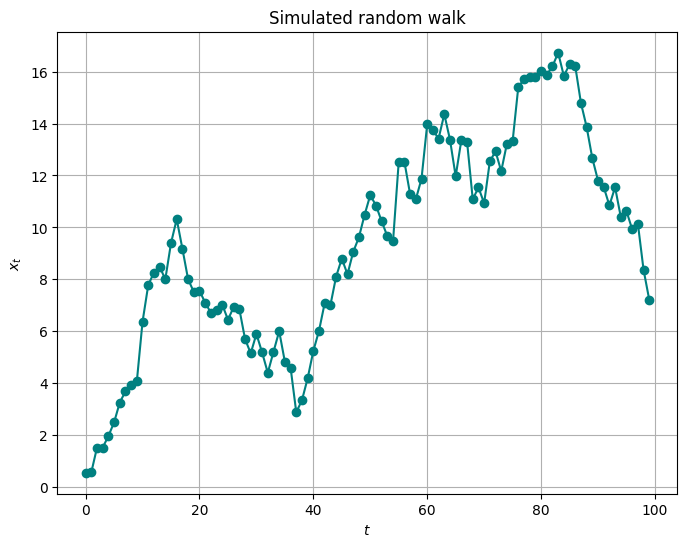
Group Task
Qualitatitvely, what can you tell about this trajectory as opposed to the AR(1)?
Task 25
Implement the random walk model. You may find some inspiration here.
Fit the model to the simulated data. How well is the model able to recover the parameters?
Perform posterior predictive check and visualise it.
If you are interested to learn more about (non-Bayesian) time series analaysis, see the textbook [Shumway et al., 2000].