Probability distributions and random variables#
Throughout the course we will work with probability distributions. Hence, it is important to master the basic principles of probability distributions, and learn to manipulate probabilities in code.
Probability distributions and random variables serve as tools for describing and performing calculations related to random events, specifically those whose outcomes are uncertain.
An illustrative example of such an uncertain event would be the act of flipping a coin or rolling a dice. In the former case, the potential outcomes are heads or tails.
An example of a random event from epidemiology, is the number of disease cases \(y(t)\) on a given day \(t\).
In the context of epidemiological modelling, we will encounter data of different types and origin. It is crucial to grasp the suitability of different probability distributions for modeling specific types of data.
Since the probabilistic programming language that we will be using for this course is Numpyro, also in this section we will use the implementations of distributions from this library available via import numpyro.distributions as dist
# uncomment this line on Colab
# !pip install numpyro
import jax
import jax.numpy as jnp
# distributions
import numpyro.distributions as dist
import matplotlib.pyplot as plt
# since we are using jax, we will need a random key:
rng = jax.random.PRNGKey(42)
/opt/hostedtoolcache/Python/3.11.11/x64/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Discrete distributions#
Discrete probability distributions represent the probabilities of distinct outcomes in a finite or countably infinite sample space.
The Bernoulli distribution#
A Bernoulli distribution is used to describe random events with two possible outcomes e.g. when we have a random variable \(X\) that takes on one of the two values \(x \in \{0, 1\}\) with probabilities \(1-p\) and \(p, 0 \le p \le 1\) respectively:
Here \(p\) is the probability of the ‘positive’ outcome. For example, in the case of a fair coin toss, \(p = 0.5\) so that both outcomes have a 50% chance of occurring.
We will be denoting this distribution as
or, equivalently,
Probability mass function#
A discrete probability distribution can be uniquely defined by its probability mass function (PMF).
For the Bernoulli distribution, we write the PMF as
Task 02
Convince yourself that the two definitions of the Bernoulli distribution shown above are equivalent.
Now let’s construct a Bernoulli distribution in code.
Drawing a sample#
We construct the distribution with a certain value of the parameter p:
p = jnp.array(0.5)
bernoulli = dist.Bernoulli(probs=p)
Now that we have constructed the distribution we can get a sample from it:
sample = bernoulli.sample(key=rng)
print(sample)
1
And we can evaluate the probability of observing a sample.
Note: the distribution objects in numpyro (and most other libraries for probability distributions) return log-probabilities rather than raw probabilities. This means that we need to take the exponent if we want to know the probability.
log_prob = bernoulli.log_prob(sample)
print(f"log p(X = {sample}) = {log_prob}")
print(f"p(X = {sample}) = {jnp.exp(log_prob)}")
log p(X = 1) = -0.6931471824645996
p(X = 1) = 0.5
As expected, we get a probability of 0.5.
Multiple samples#
We can also easily get multiple samples in one command by including sample_shape:
n_samps = 7
samples = bernoulli.sample(key=rng, sample_shape=(n_samps,))
print(samples)
[1 0 0 0 1 0 1]
What if we wanted to evaluate the probability of observing all of our samples?
The bernoulli object we created earlier treats each sample individually and returns the probabilities of observing each sample on its own:
individual_sample_probs = jnp.exp(bernoulli.log_prob(samples))
print(individual_sample_probs)
[0.5 0.5 0.5 0.5 0.5 0.5 0.5]
But, we can use one of the laws of probability to compute the probability of observing all of the samples together, i.e. jointly:
This is called the product rule of probability, and it says that for independent random variables, the joint probability (i.e., the probability of observing them all together) is equal to the product of the individual probabilities.
Now, let’s calculate the joint probability of our samples.
joint_prob = jnp.prod(individual_sample_probs)
print(joint_prob)
0.0078125
Visualise PMF#
Now let’s visualise the PMF:
def Bernouilli_vis(rng, p, n_samps):
# define distribution
bernoulli = dist.Bernoulli(probs=p)
# collect samples
samples = bernoulli.sample(key=rng, sample_shape=(n_samps,))
# how many ones
num_ones = (samples == 1.).sum()
# how many zeros
num_zeros = (samples == 0.).sum()
# plot
fig = plt.figure(dpi=100, figsize=(5, 3))
ax = fig.add_subplot(1, 1, 1)
ax.bar([0, 1], [num_zeros/n_samps, num_ones/n_samps], alpha=0.7, color='teal')
ax.set_xticks([0, 1])
ax.set_xlabel('Outcome (x)')
ax.set_ylabel('Probability Mass p(X=x)')
ax.set_title(f'Bernoulli Distribution (p={p})')
ax.grid(True)
plt.show()
Bernouilli_vis(rng, p=0.2, n_samps=10)
Task 03
Recreate this plot using bernoulli.log_prob(sample) functionality (see examples below).
Bernouilli_vis(rng, p=0.7, n_samps=100)
Task 04
Plot a panel of histograms where you vary probability \(p\) horizontally and number of samples \(n\) vertically. What do you observe?
Common usage#
Bernoulli distribution is commonly used as a likelihood in models with binary outcomes, such as presence or absence of a disease.
The Binomial distribution#
A binomial distribution is a discrete probability distribution that models the number of successes \(x\) in a fixed number \(n\) of independent and identical Bernoulli trials, where each trial has only two possible outcomes: “success” (represented as “1”) with probability \(p\) or “failure” (represented as “0”) with probability \(1-p\).
We will use the notation
Probability mass function#
The PMF of the Binomial distribution is
where
\(P(X = x)\) is the probability of getting exactly \(x\) successes,
\(\binom{n}{x}\) is the binomial coefficient, representing the number of ways to choose \(x\) successes out of \(n\) trials,
\(p\) is the probability of success on a single trial,
\(1-p\) is the probability of failure on a single trial,
the number of successes \(x\) ranges from \(0\) to \(n\) inclusive.
Task 05
Compute \(\sum_{x=0}^n P(X=x)\).
Drawing a sample#
As before, we begin by constructing the distribution:
p = 0.3
n = 10
binomial = dist.Binomial(total_count=n, probs=p)
Now we can draw a sample from this distribution:
sample = binomial.sample(key=rng)
print(sample)
3
Task 06
Draw several samples from this distribution using different keys. And draw repeatedly several samples with the same key. What do you conclude about the role of key in reproducibility of numerical experiments?
What is the probability to observe this sample?
log_prob = binomial.log_prob(sample)
print(f"log p(X = {sample}) = {log_prob}")
print(f"p(X = {sample}) = {jnp.exp(log_prob)}")
log p(X = 3) = -1.321150541305542
p(X = 3) = 0.26682811975479126
Multiple samples#
Let us generate several samples:
n_samps = 7
samples = binomial.sample(key=rng, sample_shape=(n_samps,))
print(samples)
[3 3 5 4 1 3 4]
Individual probabilities to observe the samples:
individual_sample_probs = jnp.exp(binomial.log_prob(samples))
print(individual_sample_probs)
[0.26682812 0.26682812 0.10291947 0.20012105 0.12106086 0.26682812
0.20012105]
Assuming that the samples are independent, what is the joint probability of observeing them?
joint_prob = jnp.prod(individual_sample_probs)
print(joint_prob)
9.479416e-06
Visualise PMF#
def binomial_vis(rng, p, n, x_ticks=True):
# Binomial distribution with `n` trials and probability of success `p``
binomial = dist.Binomial(total_count=n, probs=p)
# generate the possible outcomes (x values)
x_values = jnp.arange(0, n + 1)
pmf_values = jnp.exp(binomial.log_prob(x_values))
# create a bar plot (PMF plot)
fig = plt.figure(dpi=100, figsize=(5, 3))
plt.bar(x_values, pmf_values, align='center', alpha=0.7, color='teal')
plt.xlabel('Number of successes (x)')
plt.ylabel('Probability mass p(X=x)')
plt.title(f'Binomial distribution (n={n}, p={p})')
if x_ticks:
plt.xticks(x_values)
plt.grid( linestyle='--', alpha=0.7)
plt.show()
binomial_vis(rng, p=0.2, n=6)
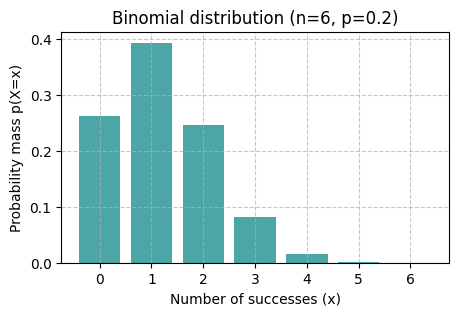
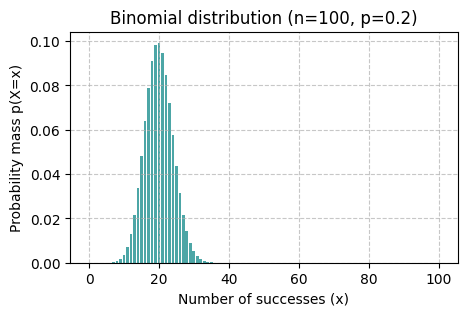
binomial_vis(rng, p=0.2, n=100, x_ticks=False)
Task 07
What is qualitatively different between the shapes of distributions Binomial(p=0.2, n=6) and Binomial(p=0.2, n=100)?
Common usage#
Binomial distribution is commonly used as a likelihood in models with binary outcomes with multiple experiments. For example, to model disease prevalence.
The Categorical distribution#
A categorical distribution is used to model random events with multiple discrete unordered outcomes, such as the die-rolling event from above.
We can characterise the categorical distribution with its PMF:
where \(K\) is the number of possible outcomes, \(p_k\) is the probability of the \(k\)th outcome, and \(I_{x=k}\) is the indicator function which evaluates to 1 if \(x = k\) and 0 otherwise. All probabilities \(p_k\) form a vector
such that
Task 08
Explain why a categorical distribution with \(K = 2\) is equivalent to a Bernoulli distribution.
ps = jnp.array([0.1, 0.2, 0.3, 0.4])
categorical = dist.Categorical(probs=ps)
As before we can take some samples:
samples = categorical.sample(key=rng, sample_shape=(10,))
print(samples)
[2 3 3 2 2 2 0 3 3 3]
print(f"p(X=0) = {jnp.exp(categorical.log_prob(0)):.1f}")
print(f"p(X=1) = {jnp.exp(categorical.log_prob(1)):.1f}")
print(f"p(X=2) = {jnp.exp(categorical.log_prob(2)):.1f}")
print(f"p(X=3) = {jnp.exp(categorical.log_prob(3)):.1f}")
p(X=0) = 0.1
p(X=1) = 0.2
p(X=2) = 0.3
p(X=3) = 0.4
We can use an alternative way to represent the categorical distribution. Instead of specifying the probabilities \(p_k\), we specify logits \(l_k\). Each \(p_k\) is then computed as
i.e., using the softmax function.
l_0 = 0.7
l_1 = 0.3
l_2 = 2
l_3 = 1.6
logits = jnp.array([l_0, l_1, l_2, l_3], dtype=jnp.float32)
categorical = dist.Categorical(logits=logits)
samples = categorical.sample(key=rng, sample_shape=(1000,))
values =[0, 1, 2, 3]
num_bins = len(values)
hist, _ = jnp.histogram(samples, bins=num_bins, density=True)
fig = plt.figure(dpi=100, figsize=(5, 3))
plt.bar(values, hist, color='teal', alpha=0.7)
plt.xticks(values)
plt.xlabel('x')
plt.ylabel('p(X=x)')
plt.grid(linestyle='--', alpha=0.7)
plt.show()
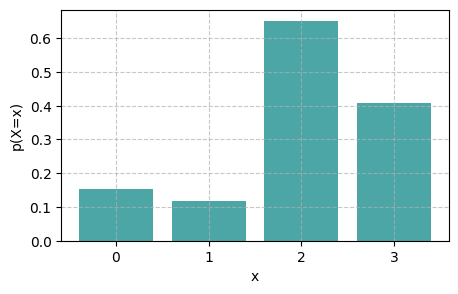
The Ordinal distribution#
The ordinal distribution is a probability distribution used to model outcomes that are ranked or ordered, often encountered in scenarios where data points lack clear numerical interpretation but possess a defined order of precedence. It assigns probabilities to different rank orders, capturing the relative likelihood of each outcome’s position within the ordered set.
# define study hours for each student
study_hours = jnp.array([5, 7, 3, 10, 8, 6, 4, 9, 2, 7])
# define cutpoints for the ordered categories
cutpoints = jnp.array([0., 5., 7., 10.]) # Ordered categories: (0, 5], (5, 7], (7, 10]
# sample logits (unnormalized probabilities) based on study hours
logits = 0.5 * study_hours
ordinal = dist.OrderedLogistic(logits, cutpoints)
# sample from the OrderedLogistic distribution
ordinal = dist.OrderedLogistic(logits, cutpoints)
samples = ordinal.sample(rng, (1000,))
Continuous distributions#
Continuous probability distributions describe the probabilities of outcomes within a continuous range of values.
The Beta distribution#
The Beta distribution is a continuous distribution with support in \([0,1] \subset \mathbb{R}\). The Beta distribution can be used to describe a continuous random variable between 0 and 1, for example, percentages and ratios. It has the following form
where \(\alpha > 0\) and \(\beta > 0\) are the two shape parameters of the distribution, and \(\mathrm{B}\) is called the beta function.
Let’s visualise the distribution.
Task 09
Try making each parameter big or small while leaving the other at the same value.
Then try make them both big or small.
def beta_vis(a, b, x_ticks=True):
beta = dist.Beta(a, b)
x_values = jnp.linspace(0, 1, 1000)
pmf_values = jnp.exp(beta.log_prob(x_values))
fig = plt.figure(dpi=100, figsize=(5, 3))
plt.plot(x_values, pmf_values, alpha=0.7, color='teal')
plt.xlabel('x')
plt.ylabel('p(X=x)')
plt.title(f'Beta distribution (a={a}, b={b})')
if x_ticks:
plt.xticks(x_values)
plt.grid( linestyle='--', alpha=0.7)
plt.show()
beta_vis(a=4.3, b=3.2, x_ticks=False)
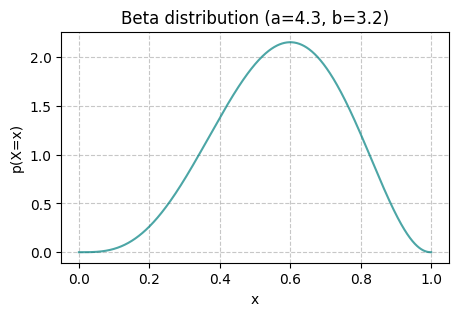
The Gamma distribution#
The Gamma distribution is a continuous distribution with support in \(\mathbb{R}^+\). Its PDF has the form
where \(\alpha>0\) is the shape parameter, which determines the shape of the distribution, and \(\beta>0\) is the scale parameter.
def gamma_vis(a, b, x_ticks=True):
gamma = dist.Gamma(a, b)
x_values = jnp.linspace(0, 20, 1000)
pmf_values = jnp.exp(gamma.log_prob(x_values))
fig = plt.figure(dpi=100, figsize=(5, 3))
plt.plot(x_values, pmf_values, alpha=0.7, color='teal')
plt.xlabel('x')
plt.ylabel('p(X=x)')
plt.title(f'Gamma distribution (a={a}, b={b})')
if x_ticks:
plt.xticks(x_values)
plt.grid( linestyle='--', alpha=0.7)
plt.show()
gamma_vis(a=2, b=0.5, x_ticks=False)
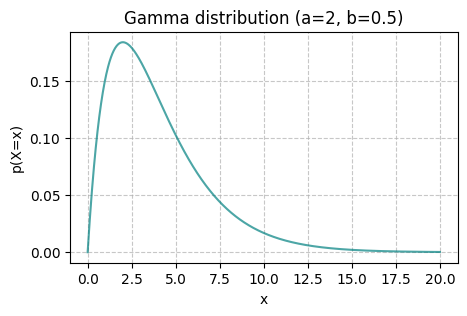
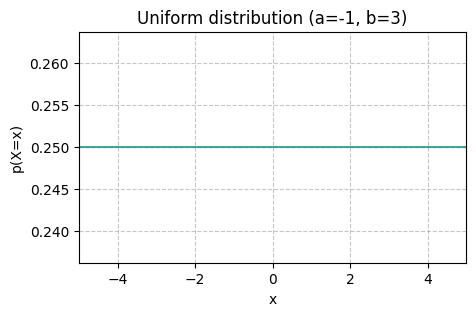
The Uniform distribution#
Perhaps, the simplest, but still a very important distribution among continuous distributions is the uniform distribution. Under this distribution, all possible values are equally likely. The uniform distribution has the following form
where \(a\) and \(b\) are the upper and lower bound parameters, respectively.
def uniform_vis(a, b, x_ticks=True):
uniform = dist.Uniform(low=a, high=b)
x_values = jnp.linspace(-5, 5, 1000)
pmf_values = jnp.exp(uniform.log_prob(x_values))
fig = plt.figure(dpi=100, figsize=(5, 3))
plt.plot(x_values, pmf_values, alpha=0.7, color='teal')
plt.xlabel('x')
plt.ylabel('p(X=x)')
plt.title(f'Uniform distribution (a={a}, b={b})')
if x_ticks:
plt.xticks(x_values)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.grid(axis='x', linestyle='--', alpha=0.7)
plt.xlim(-5, 5)
plt.show()
uniform_vis(a=-1, b=3, x_ticks=False)
The Normal distribution#
The normal – also known as Gaussian – distribution is one of the most common distributions for modeling continuous random variables, i.e., corresponding to events with an uncountable number of outcomes. Its probability density function is
where \(\mu\) and \(\sigma\) are the mean and standard deviation (also called the location, and scale or square-root of the variance \(\sigma^2\), respectively).
Task 10
How do the mean and standard deviation affect the samples?
def norm_vis(mu, sigma, x_ticks=False):
normal = dist.Normal(loc=mu, scale=sigma)
x_values = jnp.linspace(-5, 5, 1000)
pmf_values = jnp.exp(normal.log_prob(x_values))
fig = plt.figure(dpi=100, figsize=(5, 3))
plt.plot(x_values, pmf_values, alpha=0.7, color='teal')
plt.xlabel('x')
plt.ylabel('p(X=x)')
plt.title(f'Normal distribution ($\mu$={mu}, $\sigma$={sigma})')
if x_ticks:
plt.xticks(x_values)
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.grid(axis='x', linestyle='--', alpha=0.7)
plt.xlim(-5, 5)
plt.show()
norm_vis(mu = 0, sigma = 1 )
Task 11
Implement the PDF of the Normal distribution and test it using the function provided below.
def test_normal_pdf(pdf_fn, run=False):
if not run:
return
assert pdf_fn(0, 1, 0) == jnp.exp(dist.Normal(loc=0, scale=1).log_prob(0)), "Normal(X=0|0, 1) is incorrect."
assert pdf_fn(0, 2, 0) == jnp.exp(dist.Normal(loc=0, scale=2).log_prob(0)), "Normal(X=0|0, 2) is incorrect."
assert pdf_fn(0, 1, 1) == jnp.exp(dist.Normal(loc=0, scale=1).log_prob(1)), "Normal(X=0|1, 1) is incorrect."
assert pdf_fn(2, 3, 1) == jnp.exp(dist.Normal(loc=2, scale=3).log_prob(1)), "Normal(X=1|2, 3) is incorrect."
print("Nice! Your answer looks correct.")
The Multivariate Normal distribution#
The multivariate normal distribution is a generalisation of the univariate normal distribution to consider multiple random variables that have a jointly normal distribution. In other words, it lets us model variables that are not independent – if we know the value of one variable, that tells us something about the other variables! More concretely, the multivariate normal distribution lets us consider multiple random variables such that when we condition on some of these variables the remaining variables have a normal distribution. These variables are distributed in a kind of stretched fuzzy ball in higher dimensional space.
As a rule of thumb, the more one variable tells us about another, the larger the covariance or correlation between the two.
We will be using the same notation for multivatiate and univariate normals \(\mathcal{N}\). Which one to use, should be clear from the context throughout this course.
The PDF for an \(D\)-dimensional random variable \(X\):
where \(x\) and \(\mu\) are now vectors of numbers rather than single numbers, \(\Sigma\) is a covariance matrix that replaces \(\sigma\) from our univariate definition above, and \(|\Sigma|\) is its determinant. The covariance matrix looks like this:
where \(\sigma_i^2\) is the variance for the \(i\)-th dimension, and \(\rho_{ij} = \rho_{ji}\) is the correlation between the \(i\)-th and \(j\)-th dimensions. The covariance matrix tells us how the “ball” of random variables is stretched and rotated in space.
Task 12
Show that the equation above is equivalent to the univariate case when \(D = 1\)
Now let’s look at how the equation above simplifies in the two-dimensional case
Group task
Try to understand what this equation means. Discuss the following questions with your neighbors.
If \(\rho = 0\), how does this two-dimensional case relate to the one-dimensional case above?
Now, think about what happens as \(\rho\) becomes larger? What if it becomes negative?
We will come back to this distribution later in the course.
Batch and event shapes#
All distributions in numpyro have an event_shape which describes how many dimensions the random variable is, e.g., for a 2-dimensional normal distribution this would be 2, and a batch_shape which describes how many sets of parameters the distribution has – it is probably easier to show what this means with the following examples rather than tell.
Let’s first look at a simple univariate normal \(\mathcal{N}(x|0, 1)\). We will evaluate the PDFs at \(X = 1\) and \(X = 2\):
values = jnp.array([1., 2.])
normal = dist.Normal(0., 1.)
print(f"event_shape = {normal.event_shape}")
print(f"batch_shape = {normal.batch_shape}")
print(f"p(X = {values}) = {jnp.exp(normal.log_prob(values))}")
event_shape = ()
batch_shape = ()
p(X = [1. 2.]) = [0.24197073 0.05399096]
We see that this distribution has an empty event shape, which you can think of as being the same as an event shape of 1 (like how a scalar is the same as a vector of length 1). The batch shape is also empty, since we only specified one set of parameters (\(\mu = 0, \sigma = 1\)).
Now since we tried to evaluate the probability of two values at once, and neither the event shape nor the batch shape are 2, this is equivalent to calling dist.log_prob(1.) and dist.log_prob(2.) separately. numpyro is just making our lives easier by broadcasting the log_prob calculation to do both \(\mathcal{N}(X=1|0, 1)\) and \(\mathcal{N}(X=2|0, 1)\) at the same time.
We could also specify a batch of two sets of parameters so that we are essentially working with \(\mathcal{N}(x|0, 1)\) and \(\mathcal{N}(x|1, 2)\) at the same time:
batch_normal = dist.Normal(jnp.array([0., 1.]), jnp.array([1., 2.]))
print(f"event_shape = {batch_normal.event_shape}")
print(f"batch_shape = {batch_normal.batch_shape}")
print(f"[p(X_1 = {values[0]}), p(X_2 = {values[1]})] = {jnp.exp(batch_normal.log_prob(values))}")
print(f"p(X_1 = {values[0]}, X_2 = {values[1]}) = {jnp.prod(jnp.exp(batch_normal.log_prob(values)))}")
event_shape = ()
batch_shape = (2,)
[p(X_1 = 1.0), p(X_2 = 2.0)] = [0.24197073 0.17603266]
p(X_1 = 1.0, X_2 = 2.0) = 0.042594753205776215
Now, notice that while the event shape is empty (as expected since we are still working with a univariate normal), the batch size is 2!
As a result, the calculation we are doing is equivalent to separately calculating \(p(X_1=1) = \mathcal{N}(X_1=1|0, 1)\) and \(p(X_2=2) = \mathcal{N}(X_2=2|1, 2)\)! Again, this is just numpyro making our lives easier.
Note that event_shape and batch_shape correspond to the distribution we are working with, and they are related, but different from sample_shape as the examples below show.
rng = jax.random.PRNGKey(48)
normal = dist.Normal(0., 1.)
print(f"event_shape = {normal.event_shape}")
print(f"batch_shape = {normal.batch_shape}")
samples = normal.sample(key = rng, sample_shape=(3, ))
print(f"sample_shape = {samples.shape}")
event_shape = ()
batch_shape = ()
sample_shape = (3,)
batch_normal = dist.Normal(jnp.array([0., 1., 2.]), jnp.array([1., 2., 4.])) # array of means, array of vars
print(f"event_shape = {batch_normal.event_shape}")
print(f"batch_shape = {batch_normal.batch_shape}")
samples = batch_normal.sample(key = rng, sample_shape=(4, ))
print(f"sample_shape = {samples.shape}")
event_shape = ()
batch_shape = (3,)
sample_shape = (4, 3)
multivariate_full_normal = dist.MultivariateNormal(jnp.array([0., 1.]), jnp.array([[1., 1.], [1., 2.**2]]))
print(f"event_shape = {multivariate_full_normal.event_shape}")
print(f"batch_shape = {multivariate_full_normal.batch_shape}")
samples = multivariate_full_normal.sample(key = rng, sample_shape=(3, ))
print(f"sample_shape = {samples.shape}")
event_shape = (2,)
batch_shape = ()
sample_shape = (3, 2)
Measuring distances between distributions#
There are several ways to measure distances between two probability distributions with PDFs \(p(x)\) and \(q(x)\), each with its own characteristics and applications.
Total variation distance (TVD): This metric quantifies the difference between two probability distributions by measuring the total absolute difference between their probability mass functions (for discrete distributions) or probability density functions (for continuous distributions).
Kullback-Leibler Divergence (KLD): Also known as relative entropy, measures the information lost when one probability distribution is used to approximate another. It is asymmetric, and, hence is not a ‘distance’ but a ‘deviance’
Jensen-Shannon Divergence (JSD): JSD is a symmetrized version of KLD. It measures the similarity between two probability distributions by averaging their KLD values.
Hellinger Distance: This distance metric is used to measure the similarity between two probability distributions. It is based on the square root of the total variation distance and ranges between 0 and 1.
Wasserstein Distance (Earth Mover’s Distance): This metric measures the minimum amount of “work” needed to transform one distribution into another. It considers the underlying structure of the distributions and is often used in optimal transport theory. \(\Gamma(p, q)\) represents the set of all joint distributions with marginals \(p\) and \(q\). The Wasserstein distance is defined as the minimum “cost” required to transform one distribution into another.
Maximum Mean Discrepancy (MMD) between two distributions can be defined using the kernel trick. Let \(\phi(x)\) be a feature map \(\phi(x)\), and \(\mathbb{E}_{x \sim P}[ \phi(x) ]\) the expected value of the feature map \(\phi(x)\) computed over samples drawn from distribution \(p\). In the same way, \(\mathbb{E}_{y \sim Q}[ \phi(y) ]\) is the expected value of the feature map \(\phi(y)\) computed over samples drawn from distribution \(q\), \(\| \cdot \|\) is the Euclidean norm. The feature map \(\phi\) is usually chosen to be a reproducing kernel Hilbert space (RKHS) kernel function, such as the Gaussian kernel \(k(x, y) = \exp \left( -\frac{\| x - y \|^2}{2\sigma^2} \right)\).
Task 13
Implement numeric evaluation of the KL divergence:
def kl_divergence(p: dist.Distribution, q: dist.Distribution, n: int = 10_000):
"""
add your code here
"""
pass
Calculate the following KL divergence. What do we see?
\(\mathrm{KLD}\left[\mathrm{Uniform}(0, 1) \mid\mid \mathrm{Uniform}(0, 1)\right]\)
\(\mathrm{KLD}\left[\mathrm{Beta}(5, 2) \mid\mid \mathrm{Beta}(5, 2)\right]\)
Calculate the following KL divergences. What can we say about the relationship between the beta and uniform distributions?
What is \(\mathrm{KLD}\left[\mathrm{Uniform}(0, 1) \mid\mid \mathrm{Beta}(5, 2)\right]\)?
What is \(\mathrm{KLD}\left[\mathrm{Uniform}(0, 1) \mid\mid \mathrm{Beta}(2, 2)\right]\)?
What is \(\mathrm{KLD}\left[\mathrm{Uniform}(0, 1) \mid\mid \mathrm{Beta}(1, 1)\right]\)?
What is \(\mathrm{KLD}\left[ \mathrm{Beta}(5, 2) \mid\mid \mathrm{Uniform}(0, 1)\right]\). How does it compare to \(D_\mathrm{KL}\left[\mathrm{Uniform}(0, 1) \mid\mid \mathrm{Beta}(5, 2)\right]\)?
Task 14 (week 2)
Implement numeric evaluation of MMD taking as inputs two distributions
pandqof typedist.Distributions, number of samplesn. Use RBF gaussian as a default kernel.Modify the MMD computation code to accept different kernel functions besides the RBF kernel: linear, polynomial, and exponential kernels.