Logistic and other regressions#
In this section we will implement some of the GLMs.
Task 21
Notice that we are importing one new item from numpyro.infer this time: init_to_median. Research what it is doing. What are the available alternatives?
import time
import os
import numpy as np
import jax
import jax.numpy as jnp
from jax import random
import numpyro
import numpyro.distributions as dist
from numpyro.infer import MCMC, NUTS, init_to_median
import matplotlib.pyplot as plt
import arviz as az
numpyro.set_platform("cpu")
numpyro.set_host_device_count(4)
rng_key = random.PRNGKey(67)
/opt/hostedtoolcache/Python/3.11.11/x64/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Logistic regression: one dimensional version#
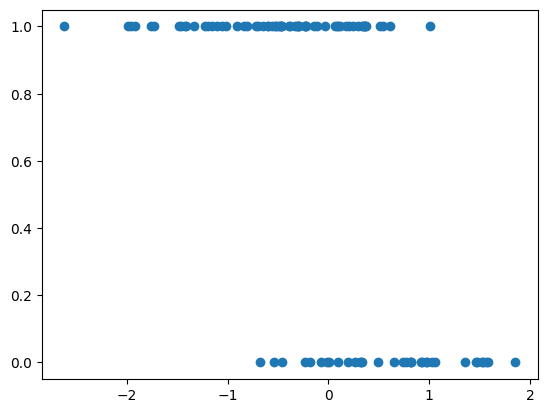
Let us simulate some data for Logistic regression and define a logistic regression model using Numpyro. We will need to choose priors for the intercept alpha and for the coefficients beta. We then will use the NUTS sampler to obtain posterior samples for alpha and beta from the Bayesian model. Finally, we will print the posterior means of the parameters.
# generate synthetic data
np.random.seed(42)
X = np.random.randn(100, 1)
true_beta = jnp.array([ -2.0])
true_alpha = 0.5
logits = jnp.dot(X, true_beta) + true_alpha
probs = 1.0 / (1.0 + jnp.exp(-logits))
y = np.random.binomial(1, probs)
plt.scatter(X, y)
<matplotlib.collections.PathCollection at 0x7f686a4baf10>
# define the logistic regression model
def logistic_regression_model(X, y=None):
# dimesionality of X, i.e the number of features
num_features = X.shape[1]
# nummber of data points
num_data = X.shape[0]
# priors
alpha = numpyro.sample('alpha', dist.Normal(0, 1))
beta = numpyro.sample('beta', dist.Normal(jnp.zeros(num_features), jnp.ones(num_features)))
# precompute logits, i.e. the linear predictor
logits = alpha + jnp.dot(X, beta)
# likelihood. Remember how to use plates?
with numpyro.plate('data', num_data):
numpyro.sample('obs', dist.Bernoulli(logits=logits), obs=y)
# define the number of MCMC samples and the number of warmup steps
num_samples = 1000
num_warmup = 500
# run NUTS
nuts_kernel = NUTS(logistic_regression_model)
mcmc = MCMC(nuts_kernel, num_samples=num_samples, num_warmup=num_warmup, progress_bar=False)
mcmc.run(rng_key, X=X, y=y)
# get posterior samples
samples = mcmc.get_samples()
# print posterior statistics
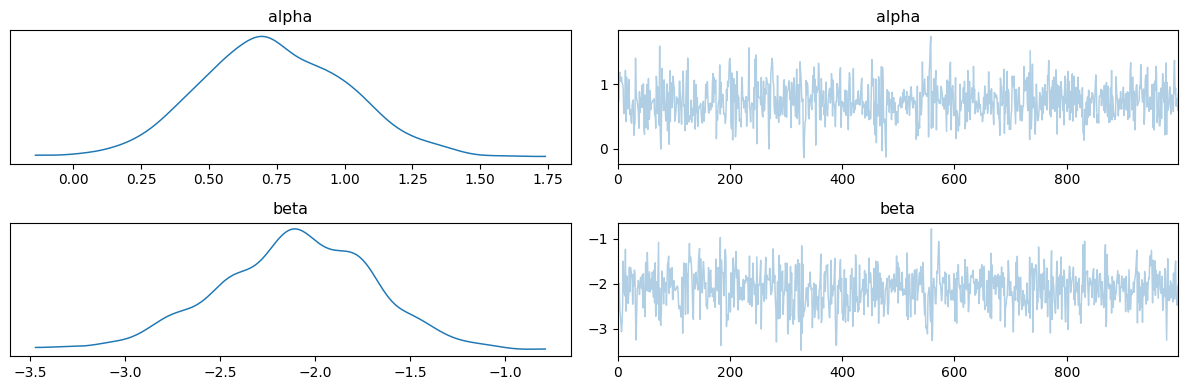
print("Posterior mean of alpha:", jnp.mean(samples['alpha']))
#print("Posterior mean of beta:", jnp.mean(samples['beta'], axis=0))
# mean is not enough
mcmc.print_summary()
# plot posterior distribution and traceplots
data = az.from_numpyro(mcmc)
az.plot_trace(data, compact=True);
plt.tight_layout()
Posterior mean of alpha: 0.7410685
mean std median 5.0% 95.0% n_eff r_hat
alpha 0.74 0.27 0.73 0.29 1.17 735.59 1.00
beta[0] -2.11 0.41 -2.10 -2.80 -1.45 599.77 1.00
Number of divergences: 0
Writing a general function for MCMC inference flow#
Note that the Numpyro model which we wrote is generic with respect to dimentionality of X (well done us!).
However, we have already repeated the same code several times. Let us wrap the inference flow into a function, and then apply to the case with two features and weights.
def run_mcmc(rng_key, # random key
model, # Numpyro model
args, # Dictionary of arguments
verbose=True # boolean for verbose MCMC
):
init_strategy = init_to_median(num_samples=10)
kernel = NUTS(model, init_strategy=init_strategy)
mcmc = MCMC(
kernel,
num_warmup=args["num_warmup"],
num_samples=args["num_mcmc_samples"],
num_chains=args["num_chains"],
thinning=args["thinning"],
progress_bar=False
)
start = time.time()
mcmc.run(rng_key, args)
t_elapsed = time.time() - start
if verbose:
mcmc.print_summary(exclude_deterministic=False)
else:
mcmc.print_summary()
print("\nMCMC elapsed time:", round(t_elapsed), "s")
# plot posterior distribution and traceplots
data = az.from_numpyro(mcmc)
az.plot_trace(data, compact=True)
plt.tight_layout()
return mcmc, mcmc.get_samples(), t_elapsed
As an input, rather than specofocally providing X and y, we will provide a dictionary args with data, as well as other parameters for MCMC.
Logistic regression: two-dimensional version#
# define the logistic regression model
def logistic_regression_model(args): # notice the `args`!
X = args["X"]
y = args["y"]
# dimesionality of X, i.e the number of features
num_features = X.shape[1]
# nummber of data points
num_data = X.shape[0]
# priors
alpha = numpyro.sample('alpha', dist.Normal(0, 1))
beta = numpyro.sample('beta', dist.Normal(jnp.zeros(num_features), jnp.ones(num_features)))
# precompute logits, i.e. the linear predictor
logits = alpha + jnp.dot(X, beta)
# likelihood. Remember how to use plates?
with numpyro.plate('data', num_data):
numpyro.sample('obs', dist.Bernoulli(logits=logits), obs=y)
# generate synthetic data
np.random.seed(42)
X = np.random.randn(100, 2)
true_beta = jnp.array([1.0, -2.0])
true_alpha = 0.5
logits = jnp.dot(X, true_beta) + true_alpha
probs = 1.0 / (1.0 + jnp.exp(-logits))
y = np.random.binomial(1, probs)
args = {'X': X,
'y':y,
'num_mcmc_samples': 1000,
'num_warmup': 500,
'num_chains': 4,
'thinning': 1,
}
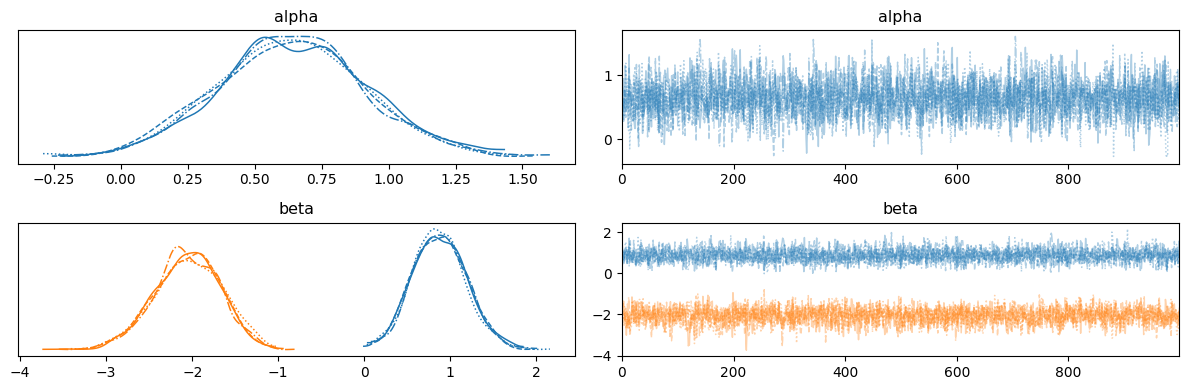
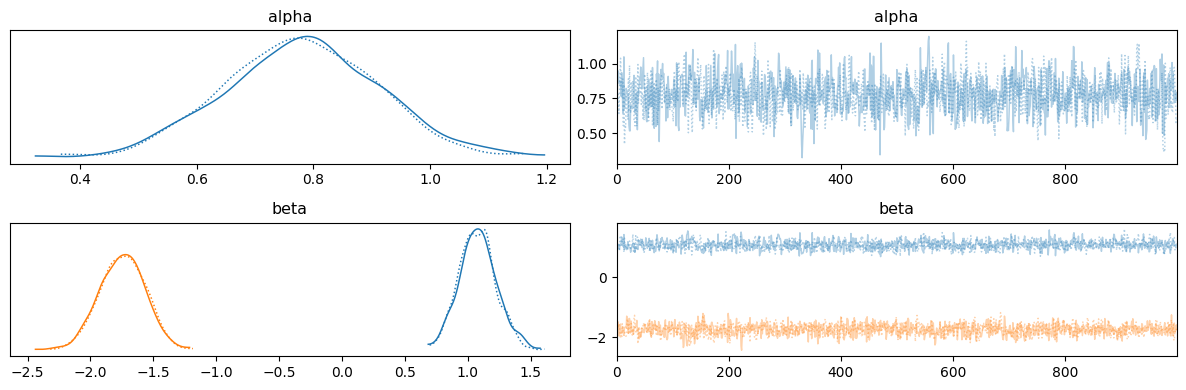
run_mcmc(rng_key, logistic_regression_model, args);
mean std median 5.0% 95.0% n_eff r_hat
alpha 0.64 0.28 0.64 0.14 1.07 2908.21 1.00
beta[0] 0.88 0.31 0.87 0.35 1.38 3000.82 1.00
beta[1] -2.06 0.39 -2.04 -2.68 -1.41 2895.88 1.00
Number of divergences: 0
MCMC elapsed time: 2 s
Poisson regression#
# generate synthetic data
np.random.seed(42)
X = np.random.randn(1000, 2)
true_beta = jnp.array([0.5, -1.5])
true_alpha = 1.0
true_lambda = jnp.exp(true_alpha + jnp.dot(X, true_beta))
y = np.random.poisson(true_lambda)
# define the Poisson regression model
def poisson_regression_model(args):
X = args["X"]
y = args["y"]
# dimesionality of X, i.e the number of features
num_features = X.shape[1]
# nummber of data points
num_data = X.shape[0]
# priors
alpha = numpyro.sample('alpha', dist.Normal(0, 1))
beta = numpyro.sample('beta', dist.Normal(jnp.zeros(num_features), jnp.ones(num_features)))
# Poisson regression
lambda_ = jnp.exp(alpha + jnp.dot(X, beta))
# likelihood
with numpyro.plate('data', num_data):
numpyro.sample('obs', dist.Poisson(lambda_), obs=y)
args = {'X': X,
'y':y,
'num_mcmc_samples': 1000,
'num_warmup': 500,
'num_chains': 2,
'thinning': 1,
}
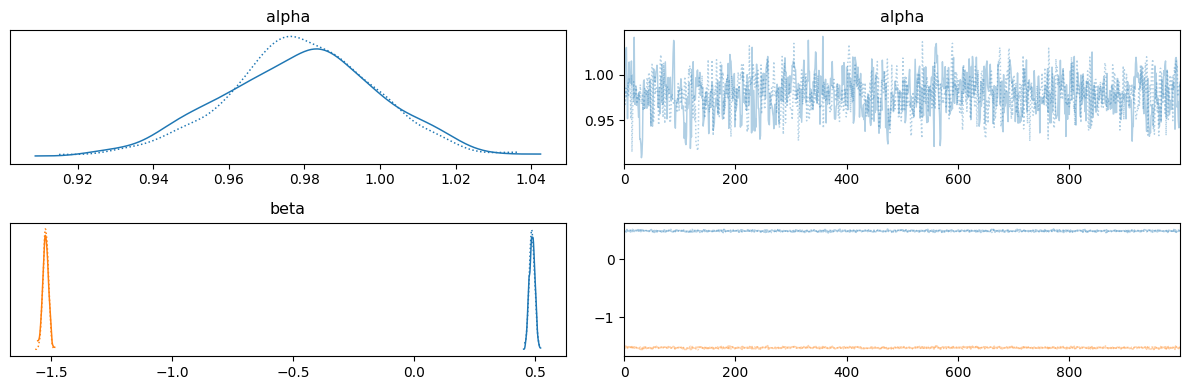
run_mcmc(rng_key, poisson_regression_model, args);
mean std median 5.0% 95.0% n_eff r_hat
alpha 0.98 0.02 0.98 0.95 1.01 818.29 1.00
beta[0] 0.49 0.01 0.49 0.47 0.51 1192.40 1.00
beta[1] -1.52 0.01 -1.52 -1.54 -1.50 869.69 1.00
Number of divergences: 0
MCMC elapsed time: 2 s
Binomial regression#
# generate synthetic data
np.random.seed(42)
num_samples = 100
X = np.random.randn(num_samples, 2)
true_beta = np.array([1.0, -2.0])
true_alpha = 1.0
logits = true_alpha + X.dot(true_beta)
num_trials = np.random.randint(1, 10, size=num_samples) # Vector of different numbers of trials
y = np.random.binomial(num_trials, p=1 / (1 + np.exp(-logits)))
# define the binomial regression model
def binomial_regression_model(args):
num_samples, num_features = X.shape
# priors for the coefficients
alpha = numpyro.sample("alpha", dist.Normal(0, 1))
beta = numpyro.sample('beta', dist.Normal(jnp.zeros(num_features), jnp.ones(num_features)))
# linear predictor
eta = alpha + jnp.dot(X, beta)
# Likelihood
with numpyro.plate('data', num_samples):
numpyro.sample('obs', dist.Binomial(total_count=num_trials, logits=eta), obs=y)
args = {'X': X,
'y':y,
'num_trials': num_trials,
'num_mcmc_samples': 1000,
'num_warmup': 500,
'num_chains': 2,
'thinning': 1,
}
run_mcmc(rng_key, binomial_regression_model, args);
mean std median 5.0% 95.0% n_eff r_hat
alpha 0.78 0.13 0.78 0.55 0.98 1180.94 1.00
beta[0] 1.08 0.15 1.08 0.83 1.32 1369.88 1.00
beta[1] -1.75 0.18 -1.74 -2.04 -1.47 1479.18 1.00
Number of divergences: 0
MCMC elapsed time: 2 s
Negative Binomial regression#
So far, we have seen only one distribution able to describe counts - the Poisson distribution. While very appealing, this distribution has such a drawback that its mean and variance are equal \(E[y] = \text{Var}[y] = \lambda\). This would not always be a good modelling choice!
The negative binomial distribution can serve as an alternative. It is also appropriate for modelling of counts, however, it allows for the mean and variance not to be equal. There exist more than one parametrizations of the negative binomial distribution. The most intuitive one is \(\mathcal{NegBin2}\) parametrisation since it connects the mean and varinace in an intuitive way:
In the limit \(\phi \to \infty\) one gets the Poisson distribution; \(\frac{\mu^2}{\phi}\) is the additional variance of the negative binomial above that of the Poisson. Parameter \(\frac{1}{\phi}\) is the overdispersion.
Group Task
Demonstrate negative binomial regression by following these steps:
simulate feature matrix
Xof dimensionality (100, 5)set true values of the intercept
alpha, coefficientsbetaand parameterphisimulate realisations
ywith these valuesconstruct a Numpyro model to estimate
alpha,betaandphifrom dataXandyfit a Poisson model to the same data. How do the two fits compare?