Bayesian workflow#
Leveraging Bayesian inference for addressing real-world problems requires from the modeller not only to be proficient in statsitics, have domain expertise and programming skills, but also a deep understanding of the decision-making process while analysing data. Apart from inference, the workflow includes iterative model building, model checking, validation and troubleshooting of computational problems, model understanding, and model comparison.
Seemingly, the Bayes rule looks very simple:
What could possibly go wrong about it in practice?
A lot can go wrong! And in case things go wrong, decisions need to be made sequentially about model building and improvement. That is why we need the Bayesian workflow.
Principles of Bayesian workflow#
Workflows exist in a variety of disciplines where they define what is a ‘good practice’.
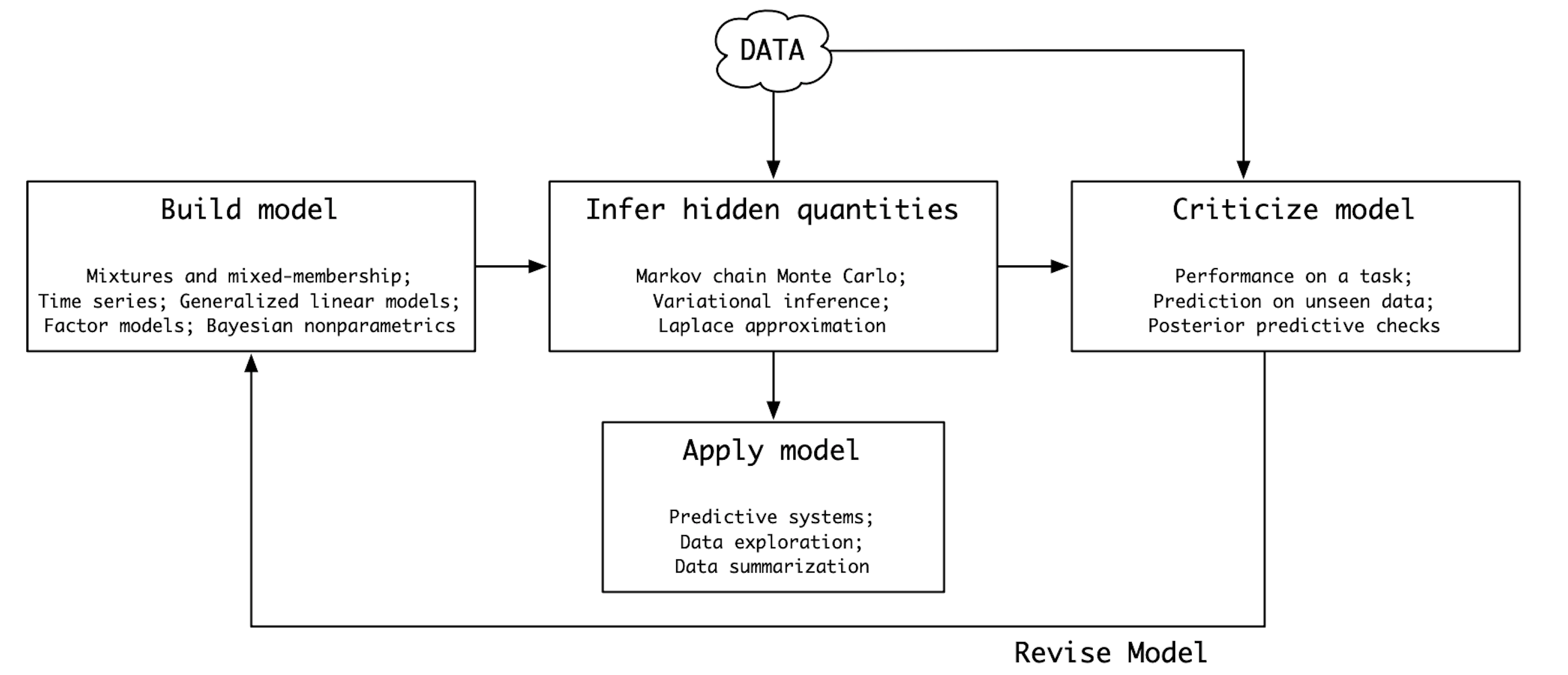
Box’s loop#
In the 1960’s, the statistician Box formulated the notion of a loop to understand the nature of the scientific method. This loop was names Box’s loop by Blei et. al. [Blei, 2014]:
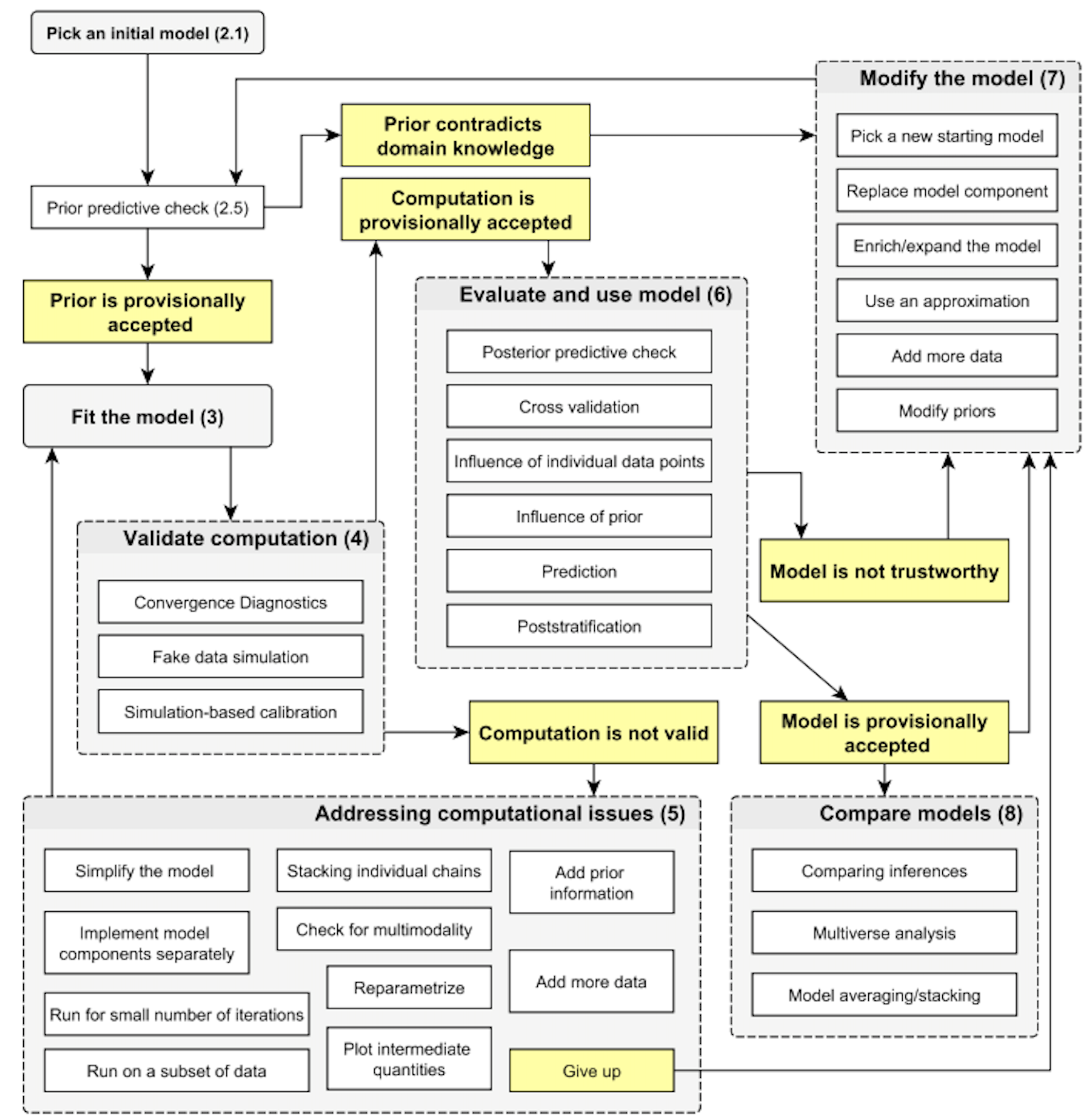
Modern Bayesian workflow#
A systematic review of the steps within the modern Bayesian workflow, described in [Gelman et al., 2020]:
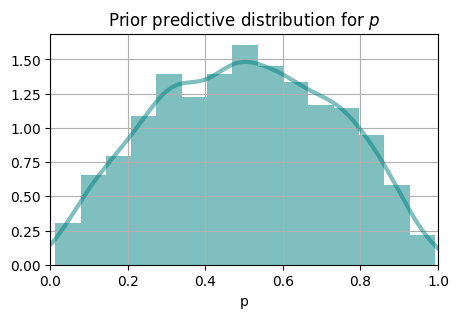
Prior predictive checks#
Prior predictive checking consists in simulating data from the priors. Then such simulations are commonly visualized (especially when transformations of parameters is involved). This shows the range of data compatible with the model, helps understand the adequacy of the chosen priors, as it is often easier to elicit expert knowledge on measureable quantities of interest rather than abstract parameter values.
Iterative model building#
A possible realisation of the Bayeisan workflow loop:
Understand the domain and problem,
Formulate the model mathematically,
Implement model, test, debug,
debug, debug, debug.
Perform prior predictive, check,
Fit the model,
Assess convergence diagnostics,
Perform posterior predictive check,
Improve the model iteratively: from baseline to complex and computationally efficient models.
Examples#
import numpyro
import numpyro.distributions as dist
from numpyro.infer import MCMC, NUTS, Predictive
from numpyro.diagnostics import hpdi
import jax
import jax.numpy as jnp
from jax import random
import arviz as az
from scipy.stats import gaussian_kde
import matplotlib.pyplot as plt
import pandas as pd
/opt/hostedtoolcache/Python/3.11.11/x64/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
Coin tossing#
Data#
n = 100 # number of trials
h = 61 # number of successes
alpha = 2 # hyperparameters
beta = 2
niter = 1000
Model#
def model(n, alpha=2, beta=2, h=None):
# prior on the probability of success p
p = numpyro.sample('p', dist.Beta(alpha, beta))
# likelihood - notice the `obs=h` part
# p is the probabiity of success,
# n is the total number of experiments
# h is the number of successes
numpyro.sample('obs', dist.Binomial(n, p), obs=h)
Prior Predictive check#
rng_key = random.PRNGKey(0)
rng_key, rng_key_ = random.split(rng_key)
# use the Predictive class to generate predictions.
# Notice that we are not passing observation `h` as data.
# Since we have set `h=None`, this allows the model to make predictions of `h`
# when data for it is not provided.
prior_predictive = Predictive(model, num_samples=1000)
prior_predictions = prior_predictive(rng_key_, n)
# we have generated samples for two variables
prior_predictions.keys()
dict_keys(['obs', 'p'])
# extract samples for variable 'p'
pred_obs = prior_predictions['p']
# compute its summary statistics for the samples of `p`
mean_prior_pred = jnp.mean(pred_obs, axis=0)
hpdi_prior_pred = hpdi(pred_obs, 0.89)
fig = plt.figure(dpi=100, figsize=(5, 3))
plt.hist(pred_obs, bins=15, density=True, alpha=0.5, color='teal')
x = jnp.linspace(0, 1, 3000)
kde = gaussian_kde(pred_obs)
plt.plot(x, kde(x), color='teal', lw=3, alpha=0.5)
plt.xlabel('p')
plt.title('Prior predictive distribution for $p$')
plt.xlim(0, 1)
plt.grid(0.3)
plt.show()
Inference#
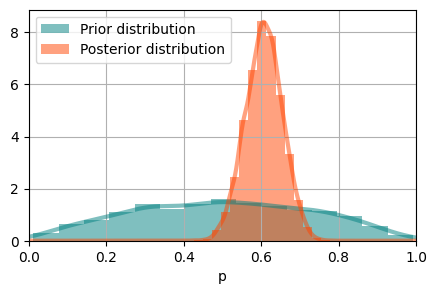
Using the same routine as we did for prior predictive, we can perform inference by using the observed data.
rng_key = random.PRNGKey(0)
rng_key, rng_key_ = random.split(rng_key)
# specify inference algorithm
kernel = NUTS(model)
# define number of samples and number chains
mcmc = MCMC(kernel, num_warmup=1000, num_samples=2000, num_chains=4, progress_bar=False, chain_method='sequential')
#run MCMC
mcmc.run(rng_key_, n=n, h=h)
# extract samples of parameter p
p_samples = mcmc.get_samples()
p_posterior_samples = p_samples['p']
fig = plt.figure(dpi=100, figsize=(5, 3))
plt.hist(pred_obs, bins=15, density=True, alpha=0.5, color='teal', label = "Prior distribution")
plt.hist(p_posterior_samples, bins=15, density=True, alpha=0.5, color='orangered', label = "Posterior distribution")
x = jnp.linspace(0, 1, 3000)
kde = gaussian_kde(pred_obs)
plt.plot(x, kde(x), color='teal', lw=3, alpha=0.5)
kde = gaussian_kde(p_posterior_samples)
plt.plot(x, kde(x), color='orangered', lw=3, alpha=0.5)
plt.xlabel('p')
plt.xlim(0, 1)
plt.grid(0.3)
plt.legend()
plt.show()
Check convergence#
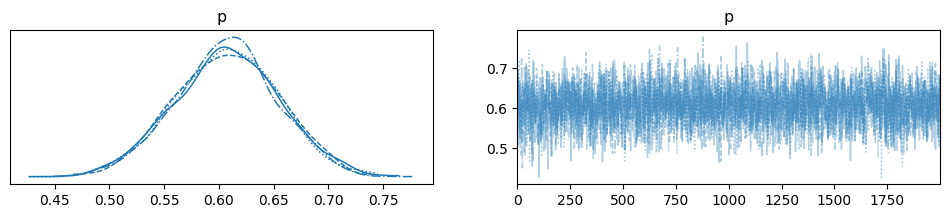
We now have obtained the samples from MCMC. How can we assess whether we can trust the results? Convergence diganostics survey this purpose. Beyond \(\hat{R}\), we can also visually inspect traceplots. Traceplots are simply sample values plotted against the iteration number. We want those traceplots to be stationary, i.e. they should look like a “hairy carterpillar”.
# inpect summary
# pring summary and look at R-hat
# r_hat is a dignostic comparing within chain variation to between chan variation.
# It is an importnat convergene diagnostic, and we want its valye to be close to 1
mcmc.print_summary()
mean std median 5.0% 95.0% n_eff r_hat
p 0.61 0.05 0.61 0.53 0.69 2753.41 1.00
Number of divergences: 0
# plot posterior distribution and traceplots
data = az.from_numpyro(mcmc)
az.plot_trace(data, compact=True);
Posterior predictive distribution#
The posterior predictive distribution is a concept in Bayesian statistics that combines the information from both the observed data and the posterior distribution of model parameters to generate predictions for new, unseen data .
We can use the obtained samples obtained at the previous step to generate posterior predictive distribution on the outcome.
# using the same 'Predictive' class,
# but now specifying also `p_samples`
rng_key, rng_key_ = random.split(rng_key)
predictive = Predictive(model, p_samples)
posterior_predictions = predictive(rng_key_, n=n)
# extract prediction and calculate summary statistics
post_obs = posterior_predictions['obs']
mean_post_pred = jnp.mean(post_obs, axis=0)
hpdi_post_pred = hpdi(post_obs, 0.9)
# what is the mean number of successes?
mean_post_pred
Array(60.663002, dtype=float32)
# what is the unceratinty around this mean?
hpdi_post_pred
array([49, 71], dtype=int32)
Group task
Change the hyperparameters of the model. How are they changing the results?
Change the data to
n=10,h=6. How does the result change now?
Bayesian Linear regression#
Now that we know how to use NumPyro. Let us build an example using larger amounts of data and build a Bayesian Linear Regression model. It is the same Linear Regression model you are familiar with, but here all of the parameters are estimated in the Bayesian way.
#!wget -O Howell1.csv https://github.com/elizavetasemenova/prob-epi/blob/main/data/Howell1.csv
df = pd.read_csv('data/Howell1.csv', sep=";")
df.head()
| height | weight | age | male | |
|---|---|---|---|---|
| 0 | 151.765 | 47.825606 | 63.0 | 1 |
| 1 | 139.700 | 36.485807 | 63.0 | 0 |
| 2 | 136.525 | 31.864838 | 65.0 | 0 |
| 3 | 156.845 | 53.041914 | 41.0 | 1 |
| 4 | 145.415 | 41.276872 | 51.0 | 0 |
# observed data
weight = df.weight.values
height = df.height.values
Let us define some test data for the variable weight. For these datapoints we will make predictions.
# data to make predictions for
weight_pred = jnp.array([45, 40, 65, 31, 53])
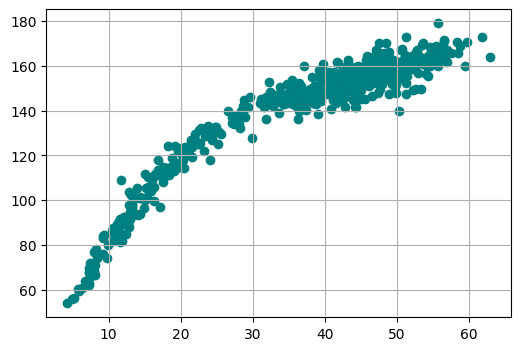
# plot the data
plt.figure(figsize=(6, 4))
plt.scatter(x='weight', y='height', data=df, color='teal')
plt.grid(0.3)
The linear regression model will have the form
Here \(y\) is the data we want to predict, \(x\) is the predictor, \(b_0\) is the bias (intercept), \(b_1\) is the slope (weight) and \(\sigma^2\) is variance.
Group task
Discuss which priors would be reasonable for the parameters \(b_0\), \(b_1\), \(\sigma\).
# model
def model(weight=None, height=None):
# priors
b0 = numpyro.sample('b0', dist.Normal(120,50))
b1 = numpyro.sample('b1', dist.Normal(0,1))
sigma = numpyro.sample('sigma', dist.HalfNormal(10.))
# deterministic transformation
mu = b0 + b1 * weight
# likelihood: notice `obs=height`
numpyro.sample('obs', dist.Normal(mu, sigma), obs=height)
# prior predictive
rng_key = random.PRNGKey(0)
rng_key, rng_key_ = random.split(rng_key)
prior_predictive = Predictive(model, num_samples=100)
prior_predictions = prior_predictive(rng_key_, weight)
prior_predictions.keys()
dict_keys(['b0', 'b1', 'obs', 'sigma'])
pred_obs = prior_predictions['obs']
mean_prior_pred = jnp.mean(pred_obs, axis=0)
hpdi_prior_pred = hpdi(pred_obs, 0.89)
def plot_regression(x, y_mean, y_hpdi, height, ttl='Predictions with 89% CI)'):
# sort values for plotting by x axis
idx = jnp.argsort(x)
weight = x[idx]
mean = y_mean[idx]
hpdi = y_hpdi[:, idx]
ht = height[idx]
# plot
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(6, 6))
ax.plot(weight, mean, color='teal')
ax.plot(weight, ht, 'o', color='orangered')
ax.fill_between(weight, hpdi[0], hpdi[1], alpha=0.3, interpolate=True, color='teal')
ax.set(xlabel='weight', ylabel='height', title=ttl);
return ax
ax = plot_regression(weight, mean_prior_pred, hpdi_prior_pred, height, ttl="Prior predictive")
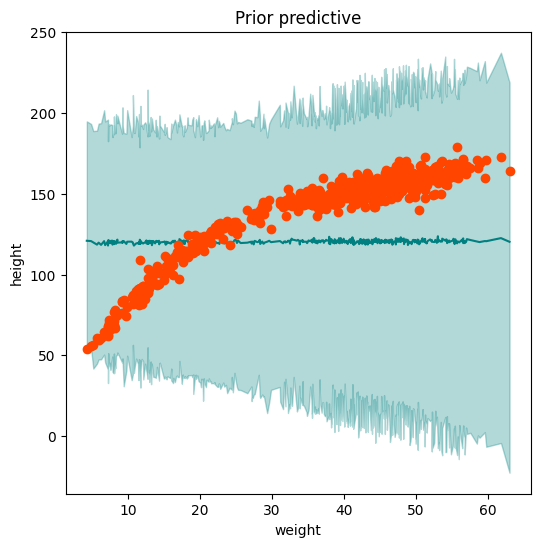
Group Task
Change the prior for \(b_0\) to dist.Normal(120,50) and visualise the prior predictive distribution. Does it look satisfactory? Do you think we can go ahead with inference using this set of priors?
# inference
rng_key = random.PRNGKey(0)
rng_key, rng_key_ = random.split(rng_key)
# run NUTS
kernel = NUTS(model)
mcmc = MCMC(kernel, num_warmup=1000, num_samples=2000, num_chains=4, progress_bar=False)
mcmc.run(rng_key_, weight=weight, height=height)
mcmc.print_summary()
samples_1 = mcmc.get_samples()
/tmp/ipykernel_2421/2150398391.py:7: UserWarning: There are not enough devices to run parallel chains: expected 4 but got 1. Chains will be drawn sequentially. If you are running MCMC in CPU, consider using `numpyro.set_host_device_count(4)` at the beginning of your program. You can double-check how many devices are available in your system using `jax.local_device_count()`.
mcmc = MCMC(kernel, num_warmup=1000, num_samples=2000, num_chains=4, progress_bar=False)
mean std median 5.0% 95.0% n_eff r_hat
b0 75.46 1.06 75.46 73.72 77.23 2731.61 1.00
b1 1.76 0.03 1.76 1.72 1.81 2742.22 1.00
sigma 9.38 0.28 9.38 8.92 9.85 4231.33 1.00
Number of divergences: 0
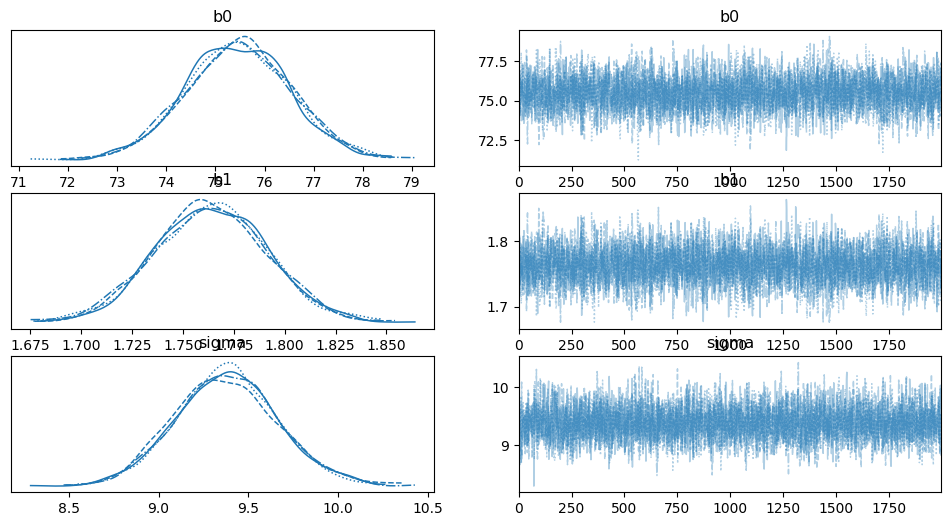
# check convergence
mcmc.print_summary()
data = az.from_numpyro(mcmc)
az.plot_trace(data, compact=True);
mean std median 5.0% 95.0% n_eff r_hat
b0 75.46 1.06 75.46 73.72 77.23 2731.61 1.00
b1 1.76 0.03 1.76 1.72 1.81 2742.22 1.00
sigma 9.38 0.28 9.38 8.92 9.85 4231.33 1.00
Number of divergences: 0
# posterior predictive
rng_key, rng_key_ = random.split(rng_key)
predictive = Predictive(model, samples_1)
posterior_predictions = predictive(rng_key_, weight=weight)
post_obs = posterior_predictions['obs']
mean_post_pred = jnp.mean(post_obs, axis=0)
hpdi_post_pred = hpdi(post_obs, 0.9)
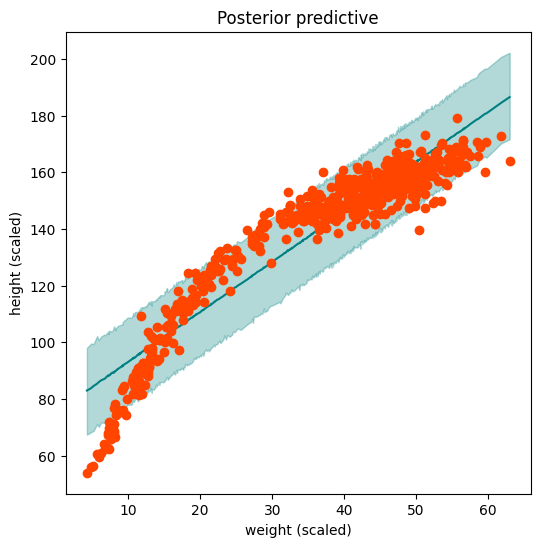
ax = plot_regression(weight, mean_post_pred, hpdi_post_pred, height, ttl="Posterior predictive")
ax.set(xlabel='weight (scaled)', ylabel='height (scaled)');
# predict for new data
predictive = Predictive(model, samples_1)
predictions = predictive(rng_key_, weight=weight_pred)['obs']
mean_pred = jnp.mean(predictions, axis=0)
hpdi_pred = hpdi(predictions, 0.89)
d = {'weight_pred': weight_pred, 'mean_pred': mean_pred, 'lower': hpdi_pred[0,], 'upper': hpdi_pred[1,]}
df_res = pd.DataFrame(data=d)
df_res.head()
| weight_pred | mean_pred | lower | upper | |
|---|---|---|---|---|
| 0 | 45 | 154.919128 | 140.484985 | 170.451385 |
| 1 | 40 | 146.193726 | 130.379166 | 160.648346 |
| 2 | 65 | 190.000656 | 174.673691 | 204.636734 |
| 3 | 31 | 130.177002 | 115.078499 | 144.936783 |
| 4 | 53 | 169.051636 | 154.488663 | 183.656372 |
Task 18
Modify the model so that it fits better.
Hint: apply a transformation to input data, e.g. a polynomial.
For this model,
plot prior predictive distribution,
perform inference,
plot posterior predictive distribution.
Why use Bayesian regression over frequentist?#
Uncertainty estimation: Bayesian regression provides a natural way to quantify uncertainty in the estimates of the model parameters. This can be useful for making probabilistic predictions and for decision-making under uncertainty. Frequentist methods typically provide point estimates and, in the best case, confidence intervals (CIs). Here we get Bayesian credible intervals (BCIs).
Handling small sample sizes: Bayesian methods can be particularly useful when dealing with small sample sizes, as they allow for more flexible modeling assumptions and can incorporate prior information to help stabilize estimates. Frequentist methods may struggle with small sample sizes, leading to unreliable estimates and inflated uncertainty.
Regularization: Bayesian regression naturally incorporates regularization techniques, such as priors that penalize large parameter values, which can help prevent overfitting and improve the generalization performance of the model. While frequentist methods also offer regularization techniques, such as Ridge regression and Lasso regression, the Bayesian framework provides a principled way to specify and interpret regularization.
Let’s unpack the regularization argument a bit more.
The linear regression model is given by:
where \(y_i\) is the response variable, \(x_i\) is the predictor variable, \(\beta_0\) and \(\beta_1\) are the regression coefficients, and \(\epsilon_i\) are idependent and normally distributed errors.
We assume normal priors for \(\beta_0\) and \(\beta_1\):
Here, \(\alpha_0\), \(\alpha_1\), \(\tau_0^2\), and \(\tau_1^2\) are hyperparameters that need to be specified. The choice of these hyperparameters can influence the strength of regularization.
The likelihood function, assuming normal errors, is:
And the priors: $\( p(\beta_0) = \frac{1}{\sqrt{2\pi\tau_0^2}} \exp\left(-\frac{(\beta_0 - \mu_0)^2}{2\tau_0^2}\right) \)\( \)\( p(\beta_1) = \frac{1}{\sqrt{2\pi\tau_1^2}} \exp\left(-\frac{(\beta_1 - \mu_1)^2}{2\tau_1^2}\right) \)$
Applying Bayes’ theorem, we get the unnormalized posterior:
Computing the log-posterior, we get
Here the first term is the mean squared error (MSE) which usually serves as an objective in frequentist machine learning, and the second term proved regularization.
Regularization is controlled through the choice of hyperparameters \(\tau_0^2\) and \(\tau_1^2\). Larger values of \(\tau_0^2\) and \(\tau_1^2\) result in stronger regularization, pushing the estimated coefficients towards zero and simplifying the model.