Hierarchical modelling#
Why are linear models not enough?#
The linear models which we considered earlier have a set of assumptions behind them which are not always realistic. Such assumptions may enable analytical derivations in some cases, but these simplifications might be too limiting when we need to model real-life data.
Epidemiological data is often complex, and we need to have appropriate tools to model complexity.
Group Task
Discuss with your neighbours how exactly the assumption of independent errors \(\epsilon_i\) in linear regression
helps in the classical setting. What does it enable us to compute analytically?
One of the simplifying assumptions is homoskedasticity, i.e. the assumption of equal or similar variances in different groups.
Sometimes it is indeed appropriate, but very often it is not.
Here is a wider list of assumptions made by linear models:
homoskedasticity: equal or similar variances in different groups,
no error in predictors \(X\),
no missing data,
normally distributed errors,
observations \(y_i\) are independent.
What we would often like to do, however, is
to model variance,
to capture errors in variables,
to allow for missing data,
use generalised linear models (GLMs),
use spatial and/or temporal error structure imposing correlation structure.
Hierarchies in data and parameters#
Hierarchical structures are commonly found in both natural data and statistical models. These hierarchies can represent various levels of organization or grouping within the data, and incorporating them into Bayesian inference can provide more accurate and insightful results. Such approach to modelling allows to account for different sources of variation in the data.
The hierarchical structure often arises in problems such as multiparameter models, where parameters can be regarded or connected in some way, or models of complex phenomena with different levels of hierarchy in the data.
Generally, a hierarchical structure can be written if the joint distribution of the parameters can be decomposed to a series of conditional distributions. The term hierarchical models refers to a general set of modelling principles rather than to a specific family of models.
Priors of model parameters are the first level of hierarchy. Priors of model parameters can depend on other parameters, and new priors (hyperpriors) are defined over these prior parameters. In this case, the hyperpriors would be the second level of hierarchy. Following this scheme, the structure can be extended to more levels of hierarchy. In principle, there is not a limited level of hierarchy.
Let us illustrate in an equation the posterior distribution of a model parameter with conditional structure and two levels of hierarchy. The prior distribution of model parameter \(\theta\), \(p(\theta|a)\), depends on the parameter \(a\); the hyperprior \(p(a|b)\) depends on a fixed value \(b\) (hyper-parameter).
The sampling order in this example follows the computational graph:
Here is a more specific example of hierarchical structure:
Due to their flexibility, hierarchical models allow us to model variability in the parameters of the model, partition variability more explicitly into multiple terms, ”borrow strength” across groups.
Levels of pooling#
Hierarchical models exist on the continuum of two extreme cases: complete pooling and no pooling. In-between the two extremes is partial pooling.
Let’s explore each of these approaches and provide Numpyro code examples.
Complete Pooling#
In the “complete pooling” approach, all data points are treated as if they belong to a single group or population, and the model estimates a single set of parameters for the entire dataset.
A pooled model implies that the data are sampled from the same model. This ignores all variation among the units being sampled. All observations share common parameter \(\theta\):
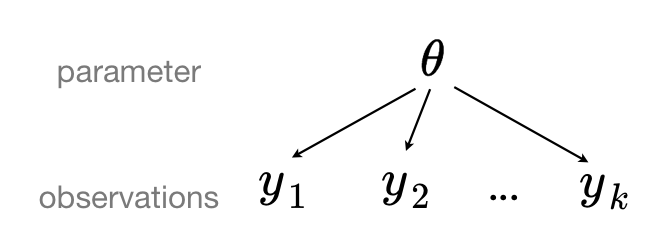
Making predictions from a complete pooling model is straightforward.
import numpyro
import numpyro.distributions as dist
from numpyro.infer import MCMC, NUTS
import jax
from jax import random
import jax.numpy as jnp
rng_key = random.PRNGKey(678)
import pandas as pd
import matplotlib.pyplot as plt
/opt/hostedtoolcache/Python/3.11.11/x64/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
# artificial data for us to work with
data = jnp.array([10, 12, 9, 11, 8]) # remember to turn data into a jnp array
# model
def complete_pooling_model(data):
mu = numpyro.sample("mu", dist.Normal(0, 10))
sigma = numpyro.sample("sigma", dist.Exponential(1))
obs = numpyro.sample("obs", dist.Normal(mu, sigma), obs=data)
# inference
nuts_kernel = NUTS(complete_pooling_model)
mcmc = MCMC(nuts_kernel, num_samples=1000, num_warmup=500, progress_bar=False)
mcmc.run(rng_key, data)
# note how many mu-s and sigma-s are estimated
mcmc.print_summary()
mean std median 5.0% 95.0% n_eff r_hat
mu 10.01 0.77 10.01 8.77 11.19 291.09 1.00
sigma 1.69 0.62 1.58 0.90 2.51 367.72 1.01
Number of divergences: 0
This approach assumes that there is no variation between data points, which can be overly restrictive when there is actual heterogeneity in the data.
No Pooling#
In the “no pooling” approach, each data point is treated independently without any grouping or hierarchical structure. This approach assumes that there is no shared information between data points, which can be overly simplistic when there is underlying structure or dependencies in the data.
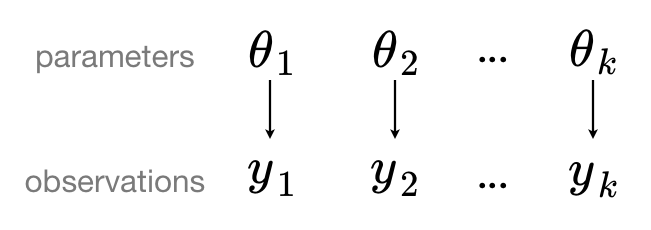
Making predictions for new data from a no pooling model is impossible since it assumes no relashionship between the previously observed and new data.
# model
def no_pooling_model(data):
for i, obs in enumerate(data):
mu_i = numpyro.sample(f"mu_{i}", dist.Normal(0, 10))
sigma_i = numpyro.sample(f"sigma_{i}", dist.Exponential(1))
numpyro.sample(f"obs_{i}", dist.Normal(mu_i, sigma_i), obs=data[i])
# inference
nuts_kernel = NUTS(no_pooling_model)
mcmc = MCMC(nuts_kernel, num_samples=1000, num_warmup=500, progress_bar=False)
mcmc.run(rng_key, data)
# note how many mu-s and sigma-s are estimated
mcmc.print_summary()
mean std median 5.0% 95.0% n_eff r_hat
mu_0 10.27 1.59 10.02 8.40 13.74 23.76 1.05
mu_1 11.93 2.07 11.97 8.72 13.56 72.43 1.01
mu_2 8.20 2.89 8.88 6.58 10.98 22.23 1.00
mu_3 10.81 0.99 10.91 9.50 12.39 149.89 1.01
mu_4 8.17 1.33 8.03 6.74 11.38 51.41 1.03
sigma_0 1.66 1.73 1.00 0.10 4.47 14.35 1.17
sigma_1 1.18 1.15 0.79 0.06 2.65 42.48 1.01
sigma_2 1.43 1.87 0.77 0.04 3.14 24.27 1.00
sigma_3 0.80 0.87 0.51 0.06 1.84 56.51 1.00
sigma_4 1.04 1.09 0.67 0.04 2.78 41.78 1.00
Number of divergences: 275
Partial Pooling#
In the “partial pooling” approach, the data is grouped into distinct categories or levels, and each group has its own set of parameters. However, these parameters are constrained by a shared distribution, allowing for both individual variation within groups and shared information across groups.
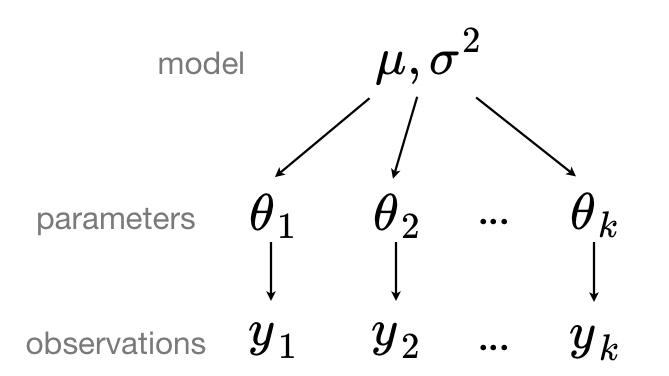
Heart attack meta-analysis#
Consider the data from a meta-analysis of heart attack data (it is from Draper, “Combining Information: Statistical Issues and Opportunities for Research”, 1992).
Each data point represents the outcome of a study on post-heart attack survivorship. Each study involved administering aspirin to some victims immediately after the heart attack, while others did not receive aspirin. The y values denote the differences in mean survivorship observed in each study. Moreover, each study provided a standard deviation, calculated based on the relative sizes of the two groups within the study.
# data
y = jnp.array([2.77, 2.50, 1.84, 2.56, 2.31, -1.15])
sd = jnp.array([1.65, 1.31, 2.34, 1.67, 1.98, 0.90])
We can build a model
where \(y_i\) is the mean of each study, and \(s_i\) is the standard deviation for each study. Parameters \(\mu\) and \(\tau\) themselves can have priors
def model(y, sd):
# hyperpriors
mu = numpyro.sample('mu', dist.Normal(jnp.mean(y), 10*jnp.std(y)))
tau = numpyro.sample('tau', dist.HalfCauchy(scale=5*jnp.std(y)))
# prior
theta = numpyro.sample('theta', dist.Normal(mu, tau), sample_shape=(len(y),))
# Likelihood
numpyro.sample('obs', dist.Normal(theta, sd), obs=y)
# inference
nuts_kernel = NUTS(model)
mcmc = MCMC(nuts_kernel, num_samples=1000, num_warmup=500, progress_bar=False)
mcmc.run(jax.random.PRNGKey(0), y=y, sd=sd)
# get posterior samples
posterior_samples = mcmc.get_samples()
# print summary statistics
numpyro.diagnostics.print_summary(posterior_samples, prob=0.89, group_by_chain=False)
mean std median 5.5% 94.5% n_eff r_hat
mu 1.59 1.10 1.57 -0.27 3.23 737.90 1.00
tau 1.93 1.09 1.69 0.35 3.29 286.71 1.00
theta[0] 2.18 1.30 2.11 0.30 4.40 733.92 1.00
theta[1] 2.11 1.08 2.10 0.39 3.72 579.22 1.00
theta[2] 1.70 1.52 1.64 -0.41 4.50 692.67 1.00
theta[3] 2.08 1.36 1.98 -0.02 4.17 724.39 1.00
theta[4] 1.81 1.44 1.81 -0.46 4.17 617.18 1.00
theta[5] -0.46 0.89 -0.46 -1.88 0.98 522.93 1.00
On the level of data, hierarchies usually are expressed in terms of groups:
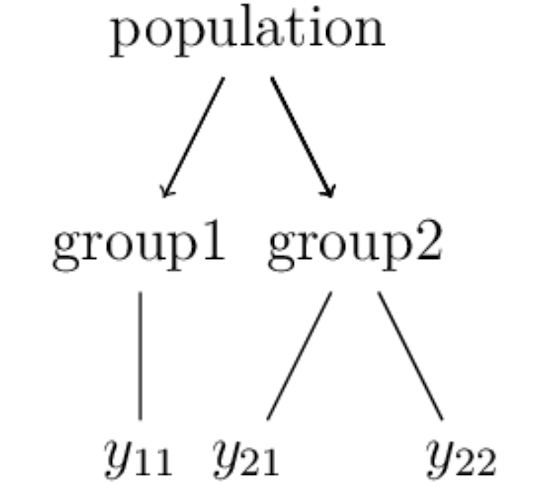
For example, \(y_{2j}\) here could represent repeated measurements within the same group.
Sleep study#
The aim of the sleep study was to assess the impact of sleep deprivation on reaction time. The sleepstudy dataset consists of records of 18 subjects. All subjects got a regular night’s sleep on “day 0” of the study, and were then restricted to 3 hours of sleep per night for the next 9 days. Each day, researchers recorded the subjects’ reaction times (in ms) on a series of tests.
!wget -O sleepstudy.csv https://raw.githubusercontent.com/elizavetasemenova/prob-epi/main/data/sleepstudy.csv
df = pd.read_csv('sleepstudy.csv')
#Drop the colum
df = df.drop('Unnamed: 0', axis=1)
df.head()
# df = pd.read_csv('data/sleepstudy.csv')
# # drop the column
# df = df.drop('Unnamed: 0', axis=1)
# df.head()
--2025-02-25 13:30:59-- https://raw.githubusercontent.com/elizavetasemenova/prob-epi/main/data/sleepstudy.csv
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.109.133, 185.199.110.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443...
connected.
HTTP request sent, awaiting response...
200 OK
Length: 4036 (3.9K) [text/plain]
Saving to: ‘sleepstudy.csv’
sleepstudy.csv 0%[ ] 0 --.-KB/s
sleepstudy.csv 100%[===================>] 3.94K --.-KB/s in 0s
2025-02-25 13:30:59 (60.3 MB/s) - ‘sleepstudy.csv’ saved [4036/4036]
/opt/hostedtoolcache/Python/3.11.11/x64/lib/python3.11/pty.py:89: RuntimeWarning: os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
pid, fd = os.forkpty()
| Reaction | Days | Subject | |
|---|---|---|---|
| 0 | 249.5600 | 0 | 308 |
| 1 | 258.7047 | 1 | 308 |
| 2 | 250.8006 | 2 | 308 |
| 3 | 321.4398 | 3 | 308 |
| 4 | 356.8519 | 4 | 308 |
Task 22
Draw a diagram showing the hierarchy in the data. What are the “groups” here?
Complete pooling:
Suppose that we took a complete pooling approach to modelling
Reactiontime (\(y\)) byDaysof sleep deprivation (\(x\)). Draw a diagram of complete pooling.Ignore the subjects and fit the complete pooling model. Visualise the result.
No pooling:
Construct and discuss separate scatterplots of Reaction by Days for each Subject.
Fit the no pooling model to the data.
Partial pooling:
Plot only data for subjects
308and335.For these two subjects, provide a loose sketch of three separate trend lines corresponding to a completely pooled, not pooled, and partially pooled model
Fit a partially poolled model and visualise the results.
Task 23
The dataset sleep.csv contains results of a small clinical trial.
In this study, ten individuals were administered a sleep aid drug, followed by another sleep aid drug. The study tracked the additional hours of sleep each participant experienced under each drug regimen, relative to their baseline measurement.
The dataset is relatively small, with a low sample size and only one predictor variable (the treatment). Luckily, the design of the experiment has a hierarchical structure.
The data for this task can be loaded as follows:
df = pd.read_csv('data/sleep.csv')
df.head()
Plot the data by showing treatment ID on the x-axis, and the number of extra hours of sleep on the y-axis. Add a separate line for each individual.
Before fitting the model, what do you think the result will be: did drug 1 have an effect? did drug 2 have an effect?
Construct a hierarchical model to analyse this data (you might want to consult this analysis for an example).
What conclusions can you make from the analysis about drug 1 and drug 2?
Random effects#
A common special case of hierarchical models are random effects.
Consider the following model with a hierarchical mean and common variance modelling outcome \(y_k\) at locations \(k\):
Often it is more convenient to write models in a slightly different form:
Here \(\mu_g\) is the global mean across all locations, and \(\alpha_k\) is a random effect which shows how each location \(k\) differs from the global mean.
Due to this way of construction, random effects always have mean 0.
Random effect variance attributes a portion of uncertainty to a specific source.
The term random effects is used to contrast the difference with fixed effects in the linear predictor:
Random effects are parts of the predictor in a model which would be different, if the experiment was replicated. And fixed effects are the parts of the model which would remain unchanged.
Random effects often include some correlation structures, such as temporal random effect and spatial random effects. They attempt to account for the unexplained variance associated with a certain group due to everything that was not measured.
Models which include both random and fixed effects are called mixed effects models, and GLMs corresponding to them become GLMMs (generalised linear mixed models).
Outro: comparison of traditional ML and Hierarchical Bayesian modelling#
Traditional ML |
Hierarchical Bayesian modelling |
|
|---|---|---|
Scale |
large |
small |
Knowledge & structure |
discard |
leverage |
Data types |
homogeneous |
heterogeneous |
Approach |
engineering-heavy, modelling light |
modelling-heavy |