Gaussian processes: inference#
In the previous chapter we have seen how to generate Gaussian process priors. But what we usually would want to do is inference, i.e. given observed data, we would like to estimate model parameters, and, potentially, make predictions at unobserved locations.
Marginalization and Conditioning#
Assume we have two sets of coordinates \(x_n = (x_n^1, x_n^2, ..., x_n^n), x_m = (x_m^1, x_m^2, ..., x_m^m)\) and a GP over them:
Marginalization allows us to extract partial information from multivariate probability distribution:
Conditioning allows us to determine the probability of one subset of variables given another subset. Similar to marginalization, this operation is also closed and yields a modified Gaussian distribution:
where
Group Task
Write down these formulas for the \(d=2\) case, i.e. when both \(f_n\) and \(f_m\) have only one component each.
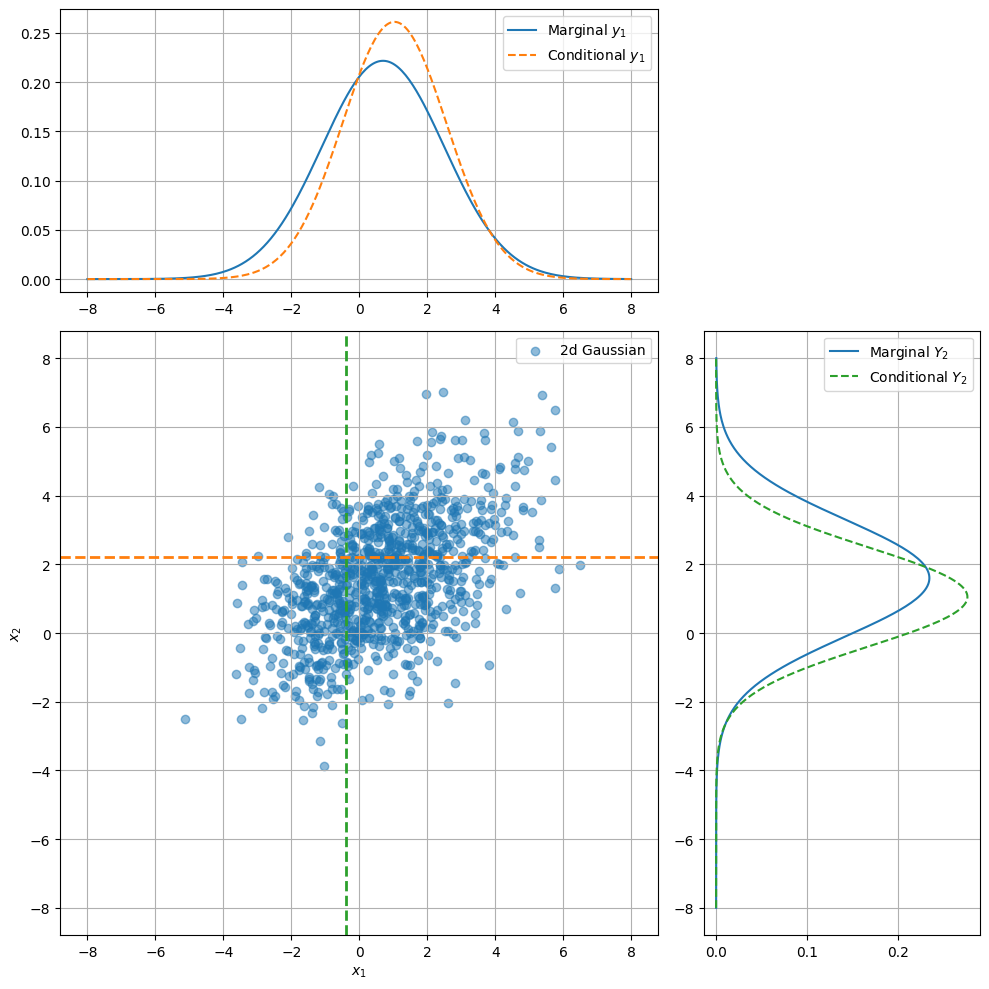
Let us visualise such a conditional.
# imports for this chapter
import numpy as np
import jax
import jax.numpy as jnp
import matplotlib.pyplot as plt
import seaborn as sns
import numpyro
import numpyro.distributions as dist
from numpyro.infer import init_to_median, Predictive, MCMC, NUTS
from numpyro.diagnostics import hpdi
import pickle
numpyro.set_host_device_count(4) # Set the device count to enable parallel sampling
/opt/hostedtoolcache/Python/3.11.11/x64/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
def Gaussian_conditional(mean, cov, x=None,y=None):
assert not (x is None and y is None) and not (x is not None and y is not None)
if x is not None:
var = cov[1,1] - cov[1,0] * cov[0,0] ** (-1) * cov[0,1]
mu = mean[1] + cov[1,0] * cov[0,0] ** (-1) * (x - mean[0])
else:
var = cov[0,0] - cov[0,1] * cov[1,1] ** (-1) * cov[1,0]
mu = mean[0] + cov[0,1] * cov[1,1] ** (-1) * (y - mean[1])
return mu, var**0.5
# parameters for the 2D Gaussian distribution
mu1 = 0.7
mu2 = 1.6
sigma1 = 1.8
sigma2 = 1.7
rho = 0.529
y1 = -0.4
y2 = 2.2
# generate data points from the 2D Gaussian distribution
mu = jnp.array([mu1, mu2])
K = jnp.array([[sigma1**2, rho*sigma1*sigma2],[rho*sigma2*sigma1, sigma2**2]])
num_samples = 1000
data = np.random.multivariate_normal(mu, K, num_samples)
# calculate marginal distributions
y_values = jnp.linspace(-8, 8, 300)
normal1 = dist.Normal(loc=mu1, scale=sigma1)
normal2 = dist.Normal(loc=mu2, scale=sigma2)
density_x1 = jnp.exp(normal1.log_prob(y_values))
density_x2 = jnp.exp(normal2.log_prob(y_values))
# compute conditionals
cond_mu_x1, cond_sigma_x1 = Gaussian_conditional(mu, K, x=None, y=y2)
cond_mu_x2, cond_sigma_x2 = Gaussian_conditional(mu, K, x=y1, y=None)
cond_density_x1 = jnp.exp(dist.Normal(loc=cond_mu_x1, scale=cond_sigma_x1).log_prob(y_values))
cond_density_x2 = jnp.exp(dist.Normal(loc=cond_mu_x2, scale=cond_sigma_x2).log_prob(y_values))
fig = plt.figure(figsize=(10, 10))
gs = fig.add_gridspec(3, 3)
# main plot (2D Gaussian distribution)
ax_main = fig.add_subplot(gs[1:3, :2])
ax_main.scatter(data[:, 0], data[:, 1], alpha=0.5, label='2d Gaussian')
ax_main.set_xlabel('$x_1$')
ax_main.set_ylabel('$x_2$')
ax_main.axvline(y1, lw=2, c='C2', linestyle = '--')
ax_main.axhline(y2, lw=2, c='C1', linestyle = '--')
ax_main.legend()
ax_main.grid(True)
# marginal x1 plot
ax_marginal_x = fig.add_subplot(gs[0, :2], sharex=ax_main)
ax_marginal_x.plot(y_values, density_x1, label='Marginal $y_1$')
ax_marginal_x.plot(y_values, cond_density_x1, label='Conditional $y_1$', linestyle = '--', c='C1')
ax_marginal_x.legend()
ax_marginal_x.grid(True)
# marginal x2 plot
ax_marginal_y = fig.add_subplot(gs[1:3, 2], sharey=ax_main)
ax_marginal_y.plot(density_x2, y_values, label='Marginal $Y_2$' )
ax_marginal_y.plot(cond_density_x2, y_values, label='Conditional $Y_2$', linestyle='--', c='C2')
ax_marginal_y.legend()
ax_marginal_y.grid(True)
plt.tight_layout()
plt.show()
Inference in GLMMs#
In a typical setting, GP enters GLMMs as a latent variable and the model has the form
Here \(\{(x_i, y_i)\}_{i=1}^n\) are pairs of observations \(y_i\), and locations of those observations \(x_i\). The role of \(f(x)\) now is to serve as a latent field capturing dependencies between locations \(x\). The expression \(\Pi_i p(y_i \vert f(x_i))\) provides a likelihood, allowing us to link observed data to the model and enabling parameter inference.
The task that we usually want to solve is twofold: we want to infer parameters involed in the model, as well as make predictions at unobserved locations \(x_*.\)
Gaussian process regression#
The simplest case of the setting described above is the Gaussian process regression where the outcome variable is modelled as a GP with added noise \(\epsilon\). It assumes that the data consists of pairs \(\{(x_i, y_i)\}_{i=1}^n\) and the likelihood is Gaussian with variance \(\sigma^2_\epsilon:\)
We want to obtain estimates at locations \(\{(x_i, y_i)\}_{i=1}^m\). Recall the conditioning formula: if
then
There is an issue with this formula since due to the noise we can not observe \(f_n\), but we observe \(y_n\) instead. The conditional in this case reads as
This is the predictive distribution of the Gaussian process.
Putting the two distributions side-by-side:
posterior distribution in the noise-free case
posterior distribution in the noisy case
Parameters \(\theta\) of the model can be learnt using the marginal log-likelihood which for the latter posterior takes the form
Computational complexity#
Note that the predictive distribution involes inversion of a \(n \times n\) matrix. This computation has cubic complexity \(O(n^3)\) with respect to the number of points \(n\) and creates a computational bottleneck when dealing with GP inference.
Let us implement the predictive distribution.
def rbf_kernel(x1, x2, lengthscale=1.0, sigma=1.0):
"""
compute the Radial Basis Function (RBF) kernel matrix between two sets of points
args:
- x1 (array): array of shape (n1, d) representing the first set of points
- x2 (array): array of shape (n2, d) representing the second set of points
- sigma (float): variance parameter
- length_scale (float): length-scale parameter
- jitter (float): small positive value added to the diagonal elementsr
returns:
- K (array): kernel matrix of shape (n1, n2)
"""
sq_dist = jnp.sum(x1**2, axis=1).reshape(-1, 1) + jnp.sum(x2**2, axis=1) - 2 * jnp.dot(x1, x2.T)
K = sigma**2 * jnp.exp(-0.5 / lengthscale**2 * sq_dist)
return K
def plot_gp(x_obs, y_obs, x_pred, mean, variance, f_true=False):
"""
plots the Gaussian process predictive distribution
args:
- x_obs: training inputs, shape (n_train_samples, n_features)
- y_train: training targets, shape (n_train_samples,)
- x_pred: test input points, shape (n_test_samples, n_features)
- mean: mean of the predictive distribution, shape (n_test_samples,)
- variance: variance of the predictive distribution, shape (n_test_samples,)
"""
plt.figure(figsize=(8, 6))
if not f_true is False:
plt.plot(x_pred, f_true, label='True Function', color='purple')
plt.scatter(x_obs, y_obs, c='orangered', label='Training Data')
plt.plot(x_pred, mean, label='Mean Prediction', color='teal')
plt.fill_between(x_pred.squeeze(), mean - jnp.sqrt(variance), mean + jnp.sqrt(variance), color='teal', alpha=0.3, label='Uncertainty')
plt.title('Gaussian Process Predictive Distribution')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid()
plt.show()
def predict_gaussian_process(x_obs, y_obs, x_pred, length_scale=1.0, sigma=1.0, jitter=1e-8):
"""
predicts the mean and variance of the Gaussian process at test points
args:
- x_obs: training inputs, shape (n_train_samples, n_features)
- y_obs: training targets, shape (n_train_samples,)
- x_pred: test input points, shape (n_test_samples, n_features)
- length_scale: length-scale parameter
- variance: variance parameter
- jitter: jitter to ensure computational stability
returns:
- mean: Mean of the predictive distribution, shape (n_test_samples,).
- variance: Variance of the predictive distribution, shape (n_test_samples,).
"""
K = rbf_kernel(x_obs, x_obs, length_scale, sigma) + jitter * jnp.eye(len(x_obs))
K_inv = jnp.linalg.inv(K)
K_star = rbf_kernel(x_obs, x_pred, length_scale, sigma)
K_star_star = rbf_kernel(x_pred, x_pred, length_scale, sigma)
mean = jnp.dot(K_star.T, jnp.dot(K_inv, y_obs))
variance = jnp.diag(K_star_star) - jnp.sum(jnp.dot(K_star.T, K_inv) * K_star.T, axis=1)
return mean, variance
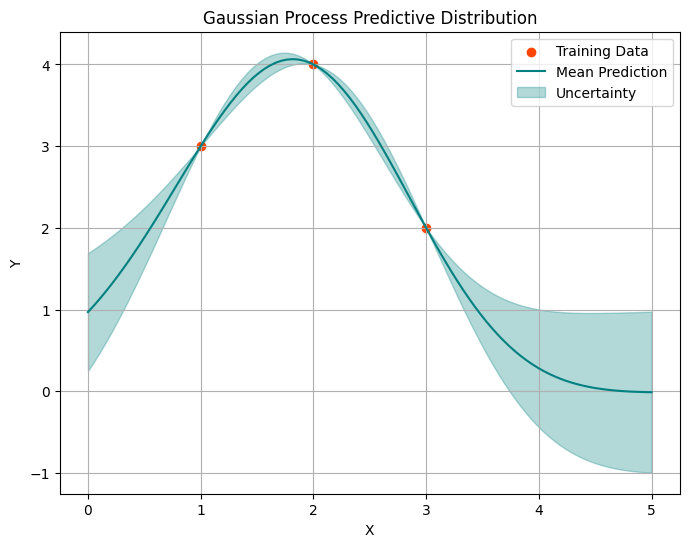
# example
x_obs = jnp.array([[1], [2], [3]]) # training inputs
y_obs = jnp.array([3, 4, 2]) # training targets
x_pred = jnp.linspace(0, 5, 100).reshape(-1, 1) # test inputs
mean, variance = predict_gaussian_process(x_obs, y_obs, x_pred)
plot_gp(x_obs, y_obs, x_pred, mean, variance)
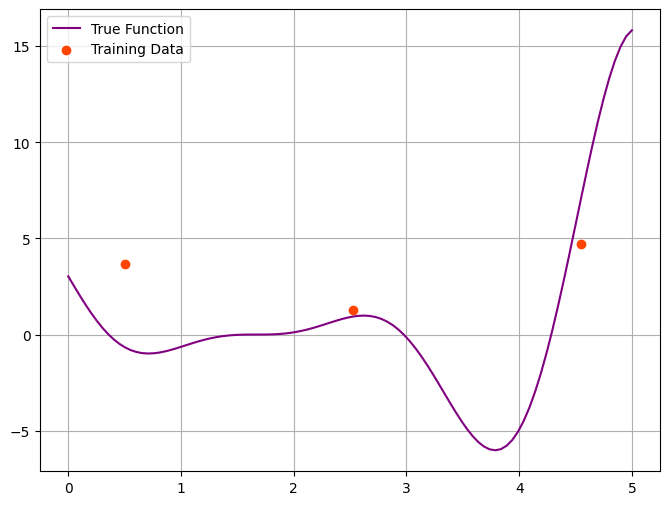
This seem to work well. Let’s take a look at some noisy data.
# the true pattern
def f(x):
return (6 * x/5 - 2)**2 * jnp.sin(12 * x/5 - 4)
# generate true function values
x = jnp.linspace(0, 5, 100)
f_true = f(x)
# sample noise with a normal distribution
noise = 2*jax.random.normal(jax.random.PRNGKey(0), shape=f_true.shape)
# add noise to the true function values to obtain the observed values (y)
y = f_true + noise
# indices of observed data points
idx_obs = jnp.array([[10], [50], [90]])
x_obs = x[idx_obs]
y_obs = y[idx_obs].reshape(-1)
plt.figure(figsize=(8, 6))
plt.plot(x, f_true, label='True Function', color='purple')
plt.scatter(x_obs, y_obs, color='orangered', label='Training Data')
plt.grid()
plt.legend()
<matplotlib.legend.Legend at 0x7f32cbf4c150>
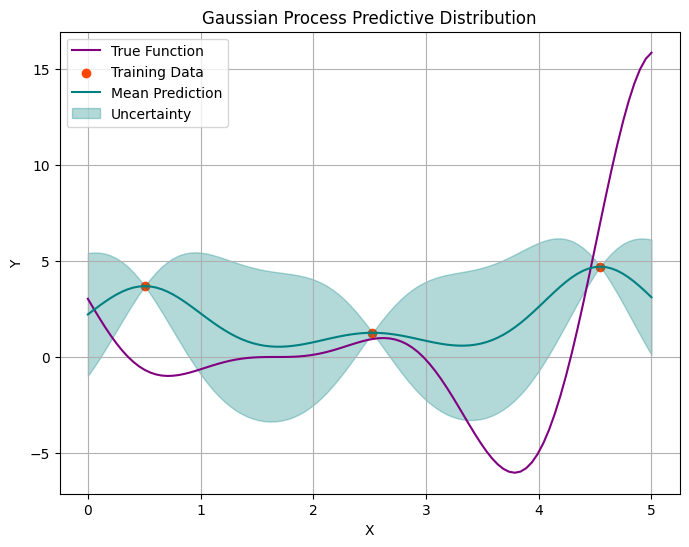
mean, variance = predict_gaussian_process(x_obs, y_obs, x_pred, length_scale=0.5, sigma=4)
plot_gp(x_obs, y_obs, x_pred, mean, variance, f_true)
Let’s add more points and repeat the procedure.
# indices of observed data points
idx_obs = jnp.array([[10], [12],[20], [68], [73], [85], [90]])
x_obs = x[idx_obs]
y_obs = y[idx_obs].reshape(-1)
mean, variance = predict_gaussian_process(x_obs, y_obs, x_pred, length_scale=0.5, sigma=4)
plot_gp(x_obs, y_obs, x_pred, mean, variance, f_true)
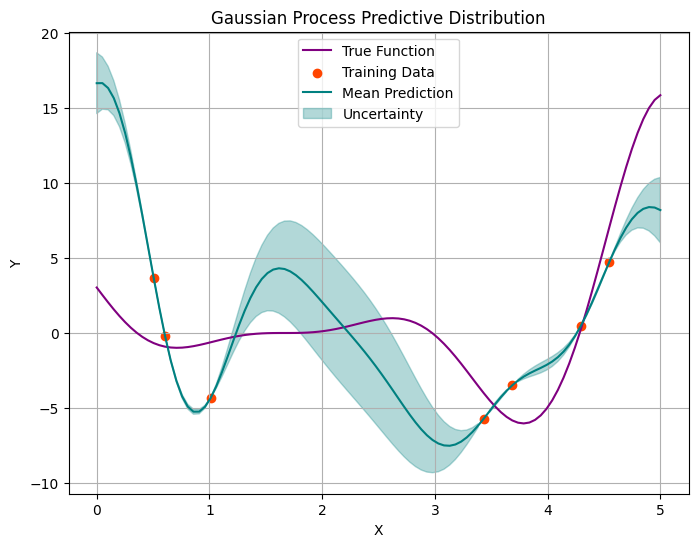
# Indices of observed data points
idx_obs = jnp.array([[5], [10], [12],[20], [25], [41], [55],[68], [73], [85], [90]])
x_obs = x[idx_obs]
y_obs = y[idx_obs].reshape(-1)
mean, variance = predict_gaussian_process(x_obs, y_obs, x_pred, length_scale=0.5, sigma=4)
plot_gp(x_obs, y_obs, x_pred, mean, variance, f_true)
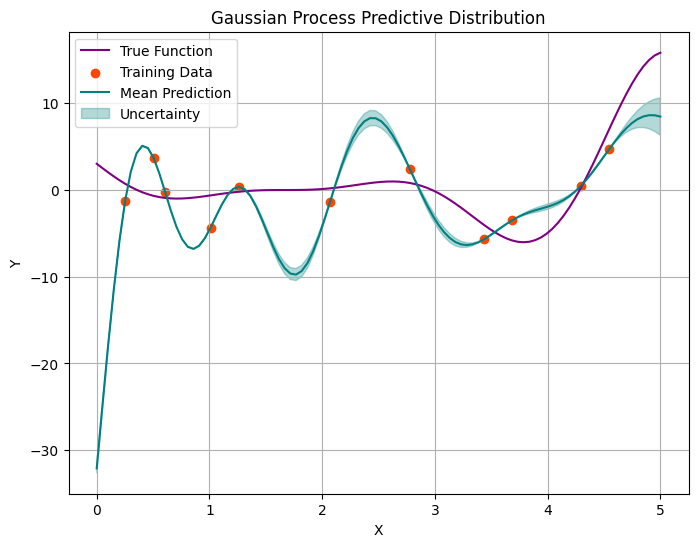
As the number of observed data points increases, we observe two phenomena. Fisrtly, the unertainty bounds are shrinking (as expected); however, rather that trying to generalise, our models starts passing through every point.
Non-Gaussian likelihoods#
We have seen that in the Normal-Normal setting, posterior distribution was accessible analytically.
For non-conjugate likelihood models this is not the case. When the likelihood is non-Gaussian, the resulting posterior distribution is no longer Gaussian, and obtaining a closed-form expression for the predictive distribution may be challenging or impossible.
In such cases, computational methods such as Markov Chain Monte Carlo or Variational Inference are often used to approximate the predictive distribution. We will use Numpyro and its MCMC engine for this purpose.
Draw GP priors using Numpyro functionality#
In the previous chapter we saw how to draw GP priors numerically. While we don’t necessarily need Numpyro to do inference in the case of Gaussian likelihood, we will soon see that we will need Numpyro for inference in other cases.
Let us start building that code by drawing GP priors using Numpyro functionality.
def plot_gp_samples(x, samples, ttl="", num_samples=10):
plt.figure(figsize=(6, 4))
for i in range(num_samples):
plt.plot(x, samples[i], label=f'Sample {i}')
plt.xlabel('x')
plt.ylabel('f(x)')
plt.title(ttl)
plt.legend()
plt.tight_layout()
plt.legend(loc='upper right', bbox_to_anchor=(1.3, 1))
plt.show()
def model(x, y=None, kernel_func=rbf_kernel, lengthcsale=0.2, jitter=1e-5, noise=0.5):
"""
Gaussian Process prior with a Numpyro model
args:
- x (jax.numpy.ndarray): input data points of shape (n, d), where n is the number of points and d is the number of dimensions
- kernel_func (function): kernel function to use
- lengthscale (float): length-scale parameter
- jitter (float): jitter for numerical stability
returns:
- numpyro.sample: a sample from the Multivariate Normal distribution representing the noisy function values at input points
"""
n = x.shape[0]
K = kernel_func(x, x, lengthcsale) + jitter*jnp.eye(n)
f = numpyro.sample("f", dist.MultivariateNormal(jnp.zeros(n), covariance_matrix=K))
numpyro.sample("y", dist.Normal(f, noise), obs=y)
n_points = 50
num_samples = 1000
# input locations
x = jnp.linspace(0, 1, n_points).reshape(-1, 1)
mcmc_predictive = Predictive(model, num_samples=num_samples)
samples = mcmc_predictive(jax.random.PRNGKey(0), x=x)
f_samples = samples['f']
# calculate mean and standard deviation
mean = jnp.mean(f_samples, axis=0)
std = jnp.std(f_samples, axis=0)
plt.figure(figsize=(8, 6))
for i in range(10):
plt.plot(x, f_samples[i], color='teal', lw=0.3)
plt.plot(x, mean, 'b-', label='Mean', color='teal') # point-wise mean of all samples
plt.fill_between(x.squeeze(), mean - 1.96 * std, mean + 1.96 * std, color='teal', alpha=0.3, label='Uncertainty Bounds') # uncertainty bounds
plt.xlabel('$x$')
plt.ylabel('$f(x)$')
plt.title('GP samples obtained using Numpyro')
plt.grid()
plt.legend()
plt.show()
/tmp/ipykernel_2893/2836025616.py:19: UserWarning: color is redundantly defined by the 'color' keyword argument and the fmt string "b-" (-> color='b'). The keyword argument will take precedence.
plt.plot(x, mean, 'b-', label='Mean', color='teal') # point-wise mean of all samples
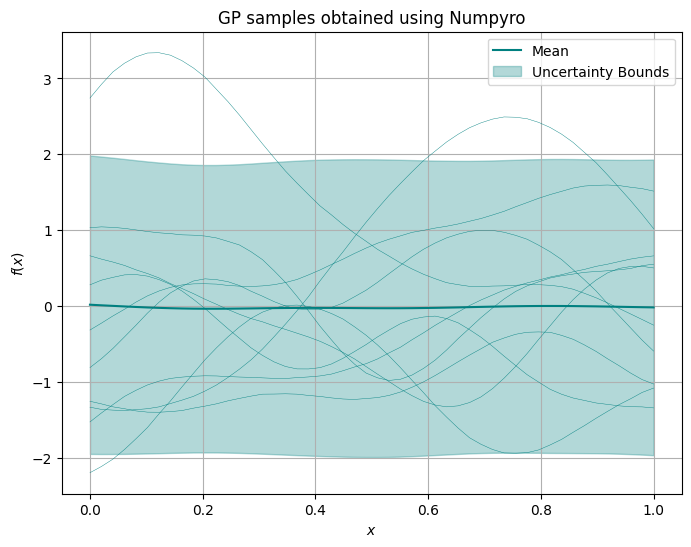
Inference with Numpyro: known noise#
For inference, we will use the simulated data in the previous step as input.
true_idx = 3
y_samples = samples['y']
f_true = f_samples[true_idx]
y_obs = y_samples[true_idx]
plt.figure(figsize=(8, 6))
plt.plot(x, f_true, label='True Function', color='purple')
plt.scatter(x, y_obs, color='orangered', label='Noisy Data')
plt.grid()
plt.legend()
<matplotlib.legend.Legend at 0x7f32c2c9bc50>
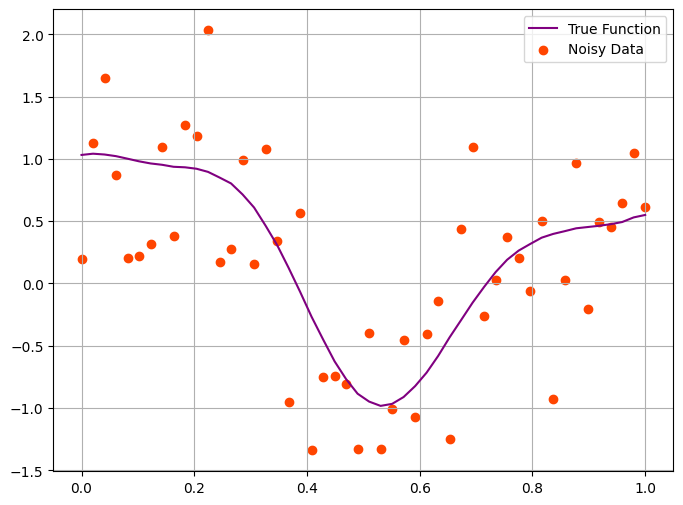
Let us see whether we can recover \(f\) from observed \(y\) values. At this stage we assume that the amount of noise is known.
nuts_kernel = NUTS(model)
mcmc = MCMC(nuts_kernel, num_samples=10000, num_warmup=2000, num_chains=2, chain_method='parallel', progress_bar=False)
mcmc.run(jax.random.PRNGKey(42), x, y_obs)
# print summary statistics of posterior
mcmc.print_summary()
# get the posterior samples
posterior_samples = mcmc.get_samples()
f_posterior = posterior_samples['f']
mean std median 5.0% 95.0% n_eff r_hat
f[0] 0.61 0.26 0.61 0.19 1.03 2227.87 1.00
f[1] 0.66 0.22 0.66 0.30 1.02 2029.69 1.00
f[2] 0.71 0.19 0.71 0.40 1.03 1885.07 1.00
f[3] 0.76 0.17 0.76 0.48 1.05 1806.10 1.00
f[4] 0.81 0.16 0.81 0.53 1.07 1789.18 1.00
f[5] 0.85 0.16 0.85 0.58 1.11 1806.92 1.00
f[6] 0.89 0.16 0.89 0.61 1.13 1827.92 1.00
f[7] 0.91 0.16 0.91 0.65 1.17 1830.43 1.00
f[8] 0.92 0.16 0.92 0.65 1.18 1799.68 1.00
f[9] 0.92 0.16 0.92 0.64 1.17 1735.86 1.00
f[10] 0.89 0.16 0.89 0.63 1.14 1657.20 1.00
f[11] 0.83 0.16 0.83 0.59 1.10 1577.61 1.00
f[12] 0.75 0.16 0.75 0.51 1.01 1504.32 1.00
f[13] 0.65 0.16 0.65 0.40 0.91 1447.64 1.00
f[14] 0.52 0.16 0.52 0.27 0.77 1408.65 1.00
f[15] 0.38 0.15 0.38 0.12 0.62 1387.64 1.00
f[16] 0.21 0.15 0.22 -0.04 0.47 1384.91 1.00
f[17] 0.04 0.15 0.04 -0.22 0.28 1397.00 1.00
f[18] -0.13 0.15 -0.13 -0.40 0.11 1415.26 1.00
f[19] -0.30 0.15 -0.30 -0.55 -0.04 1417.60 1.00
f[20] -0.46 0.15 -0.45 -0.71 -0.20 1381.16 1.00
f[21] -0.59 0.15 -0.59 -0.85 -0.34 1380.61 1.00
f[22] -0.70 0.15 -0.71 -0.98 -0.48 1361.37 1.00
f[23] -0.79 0.15 -0.79 -1.05 -0.56 1313.41 1.00
f[24] -0.84 0.15 -0.84 -1.07 -0.59 1263.28 1.00
f[25] -0.86 0.15 -0.86 -1.10 -0.61 1333.45 1.00
f[26] -0.85 0.15 -0.84 -1.07 -0.58 1391.06 1.00
f[27] -0.80 0.15 -0.80 -1.05 -0.56 1389.55 1.00
f[28] -0.74 0.15 -0.74 -0.97 -0.48 1386.93 1.00
f[29] -0.65 0.15 -0.65 -0.89 -0.40 1384.25 1.00
f[30] -0.55 0.15 -0.55 -0.80 -0.30 1383.66 1.00
f[31] -0.44 0.15 -0.44 -0.70 -0.19 1389.12 1.00
f[32] -0.33 0.16 -0.34 -0.60 -0.09 1395.58 1.00
f[33] -0.23 0.16 -0.23 -0.48 0.03 1401.24 1.00
f[34] -0.13 0.16 -0.13 -0.40 0.12 1418.95 1.00
f[35] -0.04 0.16 -0.04 -0.30 0.22 1450.77 1.00
f[36] 0.04 0.16 0.04 -0.23 0.29 1498.69 1.00
f[37] 0.11 0.16 0.11 -0.15 0.38 1561.70 1.00
f[38] 0.16 0.16 0.16 -0.10 0.42 1598.58 1.00
f[39] 0.21 0.16 0.21 -0.05 0.47 1638.42 1.00
f[40] 0.24 0.16 0.24 -0.01 0.52 1677.71 1.00
f[41] 0.28 0.16 0.28 0.03 0.56 1716.26 1.00
f[42] 0.31 0.16 0.31 0.05 0.58 1749.45 1.00
f[43] 0.34 0.16 0.34 0.08 0.60 1776.46 1.00
f[44] 0.38 0.16 0.38 0.11 0.64 1798.99 1.00
f[45] 0.41 0.17 0.41 0.14 0.69 1828.20 1.00
f[46] 0.46 0.18 0.45 0.19 0.77 1885.34 1.00
f[47] 0.50 0.19 0.49 0.19 0.82 1991.34 1.00
f[48] 0.54 0.22 0.54 0.19 0.92 2154.23 1.00
f[49] 0.59 0.26 0.58 0.16 1.00 2362.86 1.00
Number of divergences: 0
# calculate mean and standard deviation
f_mean = jnp.mean(f_posterior, axis=0)
f_hpdi = hpdi(f_posterior, 0.95)
plt.figure(figsize=(8, 6))
plt.plot(x, f_true, label='True Function', color='purple')
plt.scatter(x, y_obs, color='orangered', label='Noisy Data')
plt.plot(x, f_mean, color='teal', label='Mean Prediction')
plt.fill_between(x.squeeze(), f_hpdi[0], f_hpdi[1], color='teal', alpha=0.3, label='HPDI') # uncertainty bounds
plt.grid()
plt.legend()
plt.show()
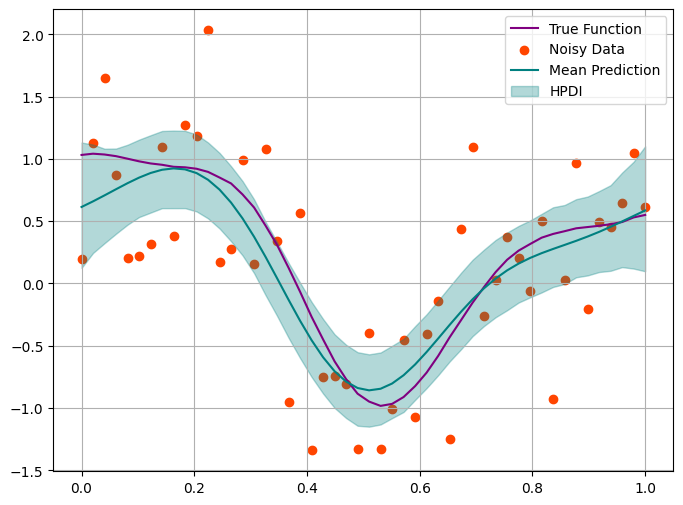
This looks good. But in reality we barely ever know true level of noise.
Inference with Numpyro: estimating noise#
def model(x, y=None, kernel_func=rbf_kernel, lengthcsale=0.2, jitter=1e-5):
"""
args:
- x (jax.numpy.ndarray): input data points of shape (n, d), where n is the number of points and d is the number of dimensions
- kernel_func (function): kernel function
- lengthscale (float): length-scale parameter
- jitter (float): jitter for numerical stability
returns:
- numpyro.sample: a sample from the Multivariate Normal distribution representing the function values at input points
"""
n = x.shape[0]
K = kernel_func(x, x, lengthcsale) + jitter*jnp.eye(n)
f = numpyro.sample("f", dist.MultivariateNormal(jnp.zeros(n), covariance_matrix=K))
sigma = numpyro.sample("sigma", dist.HalfCauchy(1))
numpyro.sample("y", dist.Normal(f, sigma), obs=y)
nuts_kernel = NUTS(model)
mcmc = MCMC(nuts_kernel, num_samples=10000, num_warmup=2000, num_chains=2, chain_method='parallel', progress_bar=False)
mcmc.run(jax.random.PRNGKey(42), x, y_obs)
# Print summary statistics of posterior
mcmc.print_summary()
# Get the posterior samples
posterior_samples = mcmc.get_samples()
mean std median 5.0% 95.0% n_eff r_hat
f[0] 0.60 0.30 0.61 0.10 1.08 2271.03 1.00
f[1] 0.65 0.26 0.65 0.23 1.08 2055.09 1.00
f[2] 0.70 0.23 0.70 0.33 1.09 1887.79 1.00
f[3] 0.76 0.21 0.76 0.41 1.11 1771.69 1.00
f[4] 0.81 0.20 0.80 0.50 1.16 1689.85 1.00
f[5] 0.85 0.19 0.85 0.55 1.18 1635.92 1.00
f[6] 0.88 0.19 0.88 0.58 1.20 1595.61 1.00
f[7] 0.91 0.19 0.90 0.59 1.22 1562.69 1.00
f[8] 0.91 0.18 0.91 0.62 1.23 1536.86 1.00
f[9] 0.90 0.18 0.90 0.62 1.23 1506.91 1.00
f[10] 0.87 0.18 0.87 0.58 1.19 1453.43 1.00
f[11] 0.81 0.18 0.81 0.52 1.11 1413.03 1.00
f[12] 0.73 0.18 0.73 0.44 1.03 1390.19 1.00
f[13] 0.62 0.18 0.62 0.35 0.93 1386.60 1.00
f[14] 0.50 0.18 0.50 0.21 0.79 1407.19 1.00
f[15] 0.36 0.18 0.36 0.08 0.64 1426.35 1.00
f[16] 0.20 0.18 0.20 -0.08 0.48 1474.29 1.00
f[17] 0.04 0.18 0.04 -0.23 0.33 1521.11 1.00
f[18] -0.13 0.18 -0.13 -0.42 0.16 1567.88 1.00
f[19] -0.29 0.18 -0.29 -0.56 0.01 1606.41 1.00
f[20] -0.44 0.18 -0.44 -0.73 -0.15 1619.26 1.00
f[21] -0.57 0.18 -0.57 -0.86 -0.28 1623.49 1.00
f[22] -0.67 0.18 -0.68 -0.97 -0.40 1626.59 1.00
f[23] -0.75 0.18 -0.76 -1.04 -0.47 1635.42 1.00
f[24] -0.81 0.18 -0.81 -1.11 -0.52 1646.83 1.00
f[25] -0.83 0.18 -0.83 -1.11 -0.53 1664.17 1.00
f[26] -0.82 0.18 -0.82 -1.10 -0.51 1681.24 1.00
f[27] -0.78 0.18 -0.78 -1.07 -0.48 1696.19 1.00
f[28] -0.72 0.18 -0.72 -1.01 -0.43 1707.25 1.00
f[29] -0.65 0.18 -0.64 -0.95 -0.36 1713.02 1.00
f[30] -0.55 0.18 -0.55 -0.86 -0.26 1713.91 1.00
f[31] -0.45 0.18 -0.45 -0.76 -0.16 1710.84 1.00
f[32] -0.35 0.18 -0.35 -0.66 -0.06 1707.22 1.00
f[33] -0.25 0.18 -0.24 -0.54 0.05 1700.98 1.00
f[34] -0.15 0.18 -0.15 -0.46 0.14 1689.22 1.00
f[35] -0.06 0.18 -0.06 -0.37 0.23 1669.61 1.00
f[36] 0.02 0.18 0.02 -0.30 0.30 1595.70 1.00
f[37] 0.09 0.18 0.09 -0.21 0.39 1509.59 1.00
f[38] 0.15 0.18 0.15 -0.15 0.44 1464.25 1.00
f[39] 0.20 0.18 0.20 -0.10 0.50 1452.87 1.00
f[40] 0.24 0.18 0.25 -0.05 0.54 1486.76 1.00
f[41] 0.28 0.18 0.29 -0.02 0.57 1557.46 1.00
f[42] 0.32 0.19 0.32 0.00 0.60 1629.43 1.00
f[43] 0.35 0.19 0.35 0.03 0.64 1684.66 1.00
f[44] 0.38 0.19 0.38 0.07 0.68 1708.57 1.00
f[45] 0.42 0.19 0.42 0.10 0.73 1742.30 1.00
f[46] 0.45 0.20 0.45 0.11 0.78 1814.72 1.00
f[47] 0.49 0.22 0.49 0.11 0.84 1955.29 1.00
f[48] 0.52 0.25 0.52 0.10 0.91 2126.22 1.00
f[49] 0.56 0.29 0.55 0.07 1.02 2338.45 1.00
sigma 0.59 0.07 0.59 0.49 0.70 3206.94 1.00
Number of divergences: 0
sigma_posterior = posterior_samples['sigma']
plt.figure(figsize=(6, 4))
sns.kdeplot(sigma_posterior, fill=True)
plt.axvline(x=0.5, color='r', linestyle='--', label='True value')
plt.xlabel('$\sigma$')
plt.ylabel('Density')
plt.title('Posterior of parameter $\sigma$')
# Show the plot
plt.show()
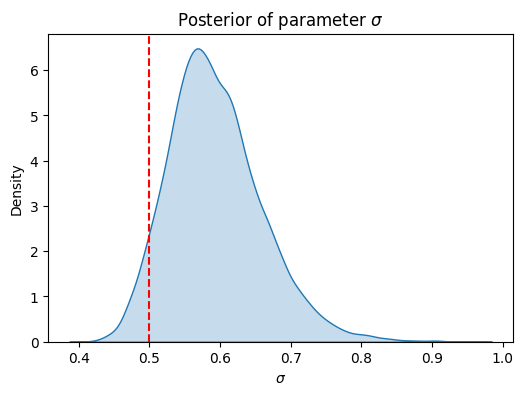
We have inferred the variance parameter successfully. Estimating lengthscale, especially for less smooth kernels is harder. One more issue is the non-identifiability of the pair lengthscale-variance. Hence, if they both really need to be inferred, strong priors would be beneficial.